Capítulo 5: Regressão Básica
Agora que estamos equipados com habilidades de visualização de dados do Capítulo 2, habilidades de manipulação de dados do Capítulo 3 e uma compreensão de como importar dados e do conceito de um formato de dados “organizado” do Capítulo 4, vamos agora prosseguir com a modelagem de dados. A premissa fundamental da modelagem de dados é tornar explícita a relação entre:
- uma variável de resultado \(y\), também chamada de variável dependente ou variável de resposta, e
- uma variável explicativa/preditora \(x\), também chamada de variável independente ou covariável.
Outra maneira de expressar isso é usando terminologia matemática: modelaremos a variável de resultado \(y\) “como uma função” da variável explicativa/preditora \(x\). Quando dizemos “função” aqui, não estamos nos referindo a funções em R, como a função ggplot(), mas sim como uma função matemática. Mas, por que temos dois rótulos diferentes, explicativo e preditor, para a variável \(x\)? Isso ocorre porque, embora os dois termos sejam frequentemente usados de forma intercambiável, falando de maneira geral, a modelagem de dados serve a um de dois propósitos:
- Modelagem para explicação: quando você deseja descrever e quantificar explicitamente a relação entre a variável de resultado \(y\) e um conjunto de variáveis explicativas \(x\), determinar a significância de quaisquer relações, ter medidas que resumam essas relações e, possivelmente, identificar quaisquer relações causais entre as variáveis.
- Modelagem para previsão: quando você deseja prever uma variável de resultado \(y\) com base nas informações contidas em um conjunto de variáveis preditoras \(x\). Diferentemente da modelagem para explicação, no entanto, você não se preocupa tanto em entender como todas as variáveis se relacionam e interagem entre si, mas sim apenas se pode fazer boas previsões sobre \(y\) usando as informações de \(x\).
Por exemplo, digamos que você está interessado em uma variável de resultado \(y\) que indica se pacientes desenvolvem câncer de pulmão e informações \(x\) sobre seus fatores de risco, como hábitos de fumar, idade e status socioeconômico. Se estivermos modelando para explicação, estaríamos interessados em descrever e quantificar os efeitos dos diferentes fatores de risco. Um motivo poderia ser que você deseja desenvolver uma intervenção para reduzir a incidência de câncer de pulmão em uma população, como utilizar publicidade para direcionar fumantes de uma faixa etária específica para programas de controle do tabagismo. Se estivermos modelando para previsão, no entanto, não nos importaríamos tanto em entender como todos os fatores de risco individuais contribuem para o câncer de pulmão, mas sim apenas se podemos fazer boas previsões de quais pessoas contrairão câncer de pulmão.
Neste livro, focaremos na modelagem para explicação e, portanto, nos referiremos a \(x\) como variáveis explicativas. Se você estiver interessado em aprender sobre modelagem para previsão, sugerimos que você confira livros e cursos na área de aprendizado de máquina (machine learning), como An Introduction to Statistical Learning with Applications in R (ISLR) (James et al., 2017). Além disso, embora existam muitas técnicas para modelagem, como modelos baseados em árvores e redes neurais, neste livro focaremos em uma técnica específica: regressão linear. A regressão linear é uma das abordagens mais comumente usadas e fáceis de entender para modelagem.
A regressão linear envolve uma variável de resultado numérica \(y\) e variáveis explicativas \(x\) que são numéricas ou categóricas. Além disso, a relação entre \(y\) e \(x\) é assumida como linear, ou em outras palavras, uma linha. No entanto, veremos que o que constitui uma “linha” variará dependendo da natureza de suas variáveis explicativas x.
No Capítulo 5 sobre regressão básica, consideraremos apenas modelos com uma única variável explicativa \(x\). Na Seção 5.1, a variável explicativa será numérica. Esse cenário é conhecido como regressão linear simples. Na Seção 5.2, a variável explicativa será categórica.
No Capítulo 6 sobre regressão múltipla, estenderemos as ideias por trás da regressão básica e consideraremos modelos com duas variáveis explicativas \(x_1\) e \(x_2\) . Na Seção 6.1, teremos duas variáveis explicativas numéricas. Na Seção 6.2, teremos uma variável explicativa numérica e outra categórica. Em particular, consideraremos dois desses modelos: modelos de interação e de inclinações paralelas.
No Capítulo 10 sobre inferência para regressão, revisitaremos nossos modelos de regressão e analisaremos os resultados usando as ferramentas de inferência estatística que você desenvolverá nos Capítulos 7, 8 e 9 sobre amostragem, bootstrap e intervalos de confiança, e teste de hipóteses e p-valores, respectivamente.
Vamos agora começar com a regressão básica, que se refere a modelos de regressão linear com uma única variável explicativa \(x\). Também discutiremos conceitos estatísticos importantes, como o coeficiente de correlação, que “correlação não é necessariamente causalidade” e o que significa para uma linha ser “melhor ajustada”.
Pacotes utilizados
Vamos agora carregar todos os pacotes necessários para este capítulo (isso pressupõe que você já os tenha instalado). Neste capítulo, apresentamos alguns pacotes novos:
- O pacote “guarda-chuva”
tidyverse(Wickham et al., 2019). Lembre-se de nossa discussão na Seção 4.4 de que carregar o pacotetidyverse, executandolibrary(tidyverse), carrega os seguintes pacotes comumente usados em ciência de dados todos de uma vez:
-
ggplot2para visualização de dados -
dplyrpara manipulação de dados -
tidyrpara converter dados para o formato “organizado” -
readrpara importar dados de planilhas para o R - Assim como os pacotes mais avançados
purrr,tibble,stringreforcats
- O pacote
broom(Robinson et al., 2023) que transforma as saídas de funções básicas do R em tibbles - O pacote
moderndive, que contém bancos de dados e funções amigáveis ao tidyverse para o aprendizado introdutório sobre regressão linear. - O pacote skimr (Waring et al., 2022), que fornece uma função de fácil utilização para calcular rapidamente uma ampla gama de estatísticas descritivas comumente usadas.
- O pacote
gapminder(Bryan, 2023), pois ele tem bancos de dados que também serão utilizados. - O pacote
gt(Iannone et al., 2023) que é utilizado para criar tabelas. - O pacote
janitor, que tem várias aplicações, mas, por hora, vamos utilizá-lo para deixar os nomes das variáveis mais adequados.
Se necessário, leia a Seção 1.3 para informações sobre como instalar e carregar pacotes no R.
5.1 Uma variável explicativa numérica
Por que alguns professores e instrutores em universidades e faculdades recebem avaliações altas dos alunos sobre a qualidade do ensino, enquanto outros recebem notas mais baixas? Existem diferenças nas avaliações sobre o ensino entre instrutores de diferentes grupos demográficos? Poderia haver um impacto devido a preconceitos dos alunos? Essas são todas questões de interesse para administradores de universidades e faculdades, pois as avaliações sobre a qualidade do ensino estão entre os muitos critérios considerados para determinar quais instrutores e professores são promovidos.
Pesquisadores da Universidade do Texas em Austin, Texas (UT Austin), tentaram responder à seguinte questão de pesquisa: quais fatores explicam as diferenças nas pontuações de avaliações sobre o ensino dos instrutores? Para isso, eles coletaram informações de instrutores e cursos em 463 cursos. Uma descrição completa do estudo pode ser encontrada em openintro.org.
Nesta seção, manteremos as coisas simples por enquanto e tentaremos explicar as diferenças nas pontuações de ensino dos instrutores como uma função de uma variável numérica: a pontuação de “beleza” do instrutor (descreveremos como essa pontuação foi determinada em breve). Instrutores com pontuações de “beleza” mais altas também têm avaliações sobre o ensino mais altas? Em sentido oposto, instrutores com pontuações de “beleza” mais altas tendam a ter avaliações sobre o ensino mais baixas? Não há relação entre a pontuação de “beleza” e as avaliações sobre o ensino? Responderemos a essas perguntas modelando a relação entre as pontuações de ensino e as pontuações de “beleza” usando regressão linear simples, onde temos:
- Uma variável de resultado numérica \(y\) (a pontuação de ensino do instrutor) e
- Uma única variável explicativa numérica \(x\) (a pontuação de “beleza” do instrutor).
5.1.1 Análise de dados exploratória
Os dados dos 463 cursos na UT Austin podem ser encontrados no banco de dados evals incluído no pacote moderndive. No entanto, para simplificar, vamos utilizar a função select() para lidar apenas com o subconjunto de variáveis que consideraremos neste capítulo e salvar essas variáveis em um novo banco de dados chamado evals_ch5. Também vamos utilizar a função clean_names() para melhorar os nomes das variáveis e facilitar a digitação:
evals_ch5 <- evals |>
select(ID, score, bty_avg, age) |>
clean_names()Um passo crucial antes de realizar qualquer tipo de análise ou modelagem é realizar uma análise de dados exploratória (ADE, para abreviar). A ADE oferece uma noção das distribuições das variáveis individuais em seus dados, se existem potenciais relações entre variáveis, se há outliers e/ou valores ausentes, e (o mais importante) como construir seu modelo. Aqui estão três passos comuns em uma ADE:
- Mais importante, observar os valores dos dados brutos.
- Calcular estatísticas descritivas, como médias, medianas e intervalos interquartílicos.
- Visualizar os dados.
Vamos realizar o primeiro passo comum em uma ADE: olhar os valores brutos dos dados. Porque este passo parece tão trivial, infelizmente muitos analistas o ignoram. No entanto, ter uma noção inicial sobre a aparência dos seus dados pode, muitas vezes, prevenir problemas maiores mais adiante.
Você pode fazer isso usando o visualizador de planilhas do RStudio ou utilizando a função glimpse(), como introduzido na Subseção 1.4.3 sobre exploração de bancos de dados:
evals_ch5 |>
glimpse()Rows: 463
Columns: 4
$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,…
$ score <dbl> 4.7, 4.1, 3.9, 4.8, 4.6, 4.3, 2.8, 4.1, 3.4, 4.5, 3.8, 4.5, 4.…
$ bty_avg <dbl> 5.000, 5.000, 5.000, 5.000, 3.000, 3.000, 3.000, 3.333, 3.333,…
$ age <int> 36, 36, 36, 36, 59, 59, 59, 51, 51, 40, 40, 40, 40, 40, 40, 40…Observe que Rows: 463 indica que existem 463 linhas/observações em evals_ch5, onde cada linha corresponde a um curso observado na UT Austin. É importante notar que a unidade de observação é um curso individual e não um instrutor individual. Lembre-se da Subseção 1.4.3: a unidade de observação é o “tipo de coisa” que está sendo medida pelas nossas variáveis. Uma vez que os instrutores ensinam mais de um curso em um ano acadêmico, o mesmo instrutor aparecerá mais de uma vez nos dados. Portanto, há menos de 463 instrutores únicos representados em evals_ch5. Revisitaremos essa ideia na Seção 10.3, quando falarmos sobre a “suposição de independência” para inferência na regressão.
Uma descrição completa de todas as variáveis incluídas em evals pode ser encontrada em openintro.org ou lendo o arquivo de ajuda associado (execute ?evals no console). No entanto, vamos descrever completamente apenas as 4 variáveis que selecionamos em evals_ch5:
-
id: Uma variável de identificação usada para distinguir entre os cursos de 1 a 463 no conjunto de dados. -
score: Uma variável numérica da média das notas de ensino do instrutor do curso, onde a média é calculada a partir das notas de avaliação de todos os alunos nesse curso. Notas de ensino 1 são as mais baixas e 5 são as mais altas. Esta é a variável de resultado \(y\) que vamos analisar. -
bty_avg: Uma variável numérica da média da pontuação de “beleza” do instrutor do curso, onde a média é calculada a partir de um painel separado de seis estudantes. Pontuações de “beleza” 1 são as mais baixas e 10 são as mais altas. Esta é a variável explicativa \(x\) que analisaremos. -
age: Uma variável numérica da idade do instrutor do curso. Esta será outra variável explicativa \(x\) que usaremos na “Verificação do aprendizado” no final desta subseção.
Uma maneira alternativa de olhar os valores brutos dos dados é escolhendo uma amostra aleatória das linhas em evals_ch5 utilizando a função slice_sample() do pacote dplyr. Aqui definimos o argumento n como 5, indicando que queremos uma amostra aleatória de 5 linhas. Exibimos os resultados na Tabela 1. Note que, devido à natureza aleatória da amostragem, é provável que você acabe com um subconjunto diferente de 5 linhas.Para evitar essa variação, podemos utilizar a função set.seed(), que serve para definir a semente para a geração de números aleatórios, garantindo a reprodutibilidade dos resultados.
set.seed(76)
evals_ch5 |>
slice_sample(n = 5)# A tibble: 5 × 4
id score bty_avg age
<int> <dbl> <dbl> <int>
1 129 3.7 3 62
2 109 4.7 4.33 46
3 28 4.8 5.5 62
4 434 2.8 2 62
5 330 4 2.33 64Vamos utilizar o pacote gt para criar a Tabela 1:
set.seed(76)
evals_ch5 |>
slice_sample(n = 5) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = everything()
) |>
fmt_number(
decimals = 1,
columns = c(score,bty_avg)
)| id | score | bty_avg | age |
|---|---|---|---|
| 129 | 3.7 | 3.0 | 62 |
| 109 | 4.7 | 4.3 | 46 |
| 28 | 4.8 | 5.5 | 62 |
| 434 | 2.8 | 2.0 | 62 |
| 330 | 4.0 | 2.3 | 64 |
Agora que observamos os valores brutos no nosso banco de dados evals_ch5 e obtivemos uma noção preliminar sobre eles, vamos passar para o próximo passo comum em uma ADE: calcular estatísticas descritivas. Vamos começar calculando a média e a mediana da nossa variável de resultado numérica score e da nossa variável explicativa numérica “beleza”, denominada bty_avg. Faremos isso usando a função summarize() do dplyr junto com as funções mean() e median() que vimos na Seção 3.3.
# A tibble: 1 × 4
score_M score_MD bty_avg_M bty_avg_MD
<dbl> <dbl> <dbl> <dbl>
1 4.17 4.3 4.42 4.33E se também quisermos outras estatísticas descritivas, como o desvio padrão (uma medida de dispersão), os valores mínimos e máximos e vários percentis?
Digitar todas essas funções de estatísticas descritivas na função summarise() seria longo e tedioso. Em vez disso, vamos usar a conveniente função skim() do pacote skimr. Esta função recebe um banco de dados, o “analisa” e retorna estatísticas descritivas comumente usadas. Vamos pegar nosso banco de dados evals_ch5, selecionar apenas as variáveis de resultado e explicativas score e bty_avg, e encaminhá-las para a função skim()1:
── Data Summary ────────────────────────
Values
Name select(evals_ch5, score, ...
Number of rows 463
Number of columns 2
_______________________
Column type frequency:
numeric 2
________________________
Group variables None
── Variable type: numeric ──────────────────────────────────────────────────────
skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100
1 score 0 1 4.17 0.544 2.3 3.8 4.3 4.6 5
2 bty_avg 0 1 4.42 1.53 1.67 3.17 4.33 5.5 8.17Para as variáveis numéricas score (nota de ensino) e bty_avg (nota de beleza), ela retorna:
- n_missing: o número de valores ausentes
- complete_rate: o percentual de valores não ausentes ou completos
- mean: a média
- sd: o desvio padrão
- p0: o percentil 0, o valor no qual 0% das observações são menores do que ele (o valor mínimo)
- p25: o percentil 25, o valor no qual 25% das observações são menores do que ele (o 1º quartil)
- p50: o percentil 50, o valor no qual 50% das observações são menores do que ele (o 2º quartil e mais comumente chamado de mediana)p75: o percentil 75: o valor no qual 75% das observações são menores do que ele (o 3º quartil)
- p100: o percentil 100. o valor no qual 100% das observações são menores do que ele (o valor máximo)
Olhando para essa saída, podemos ver como os valores de ambas as variáveis se distribuem. Por exemplo, a média da nota de ensino foi 4.17 de 5, enquanto a média da pontuação de “beleza” foi 4.42 de 10. Além disso, a faixa que engloba o meio dos valores das notas de ensino, ou seja, excluindo os 25% mais baixos e os 25% mais altos, variava de 3.80 a 4.6. Esses valores correspondem ao primeiro quartil (25% mais baixos) e ao terceiro quartil (75% mais altos), respectivamente. Para as pontuações de ‘beleza’, os valores que se encontram na metade central da distribuição, isto é, excluindo os 25% mais baixos e os 25% mais altos, variavam de 3.17 a 5.5 de 10. Estes valores representam, respectivamente, o primeiro quartil (25% inferior) e o terceiro quartil (25% superior) das pontuações.
A função skim() retorna apenas o que são conhecidas como estatísticas descritivas univariadas: funções que pegam uma única variável e retornam algum resumo numérico dessa variável. No entanto, também existem estatísticas descritivas bivariadas: funções que levam em conta duas variáveis e retornam algum resumo dessas duas variáveis. Em particular, quando as duas variáveis são numéricas, podemos calcular o coeficiente de correlação. De forma geral, os coeficientes são expressões quantitativas de um fenômeno específico. Um coeficiente de correlação é uma expressão quantitativa da força da relação linear entre duas variáveis numéricas. Seu valor varia entre -1 e 1, onde:
- -1 indica uma relação negativa perfeita: à medida que uma variável aumenta, o valor da outra variável tende a diminuir, seguindo uma linha reta.
- 0 indica nenhuma relação: os valores de ambas as variáveis aumentam ou diminuem independentemente um do outro.
- +1 indica uma relação positiva perfeita: à medida que o valor de uma variável sobe, o valor da outra variável tende a subir também de maneira linear.
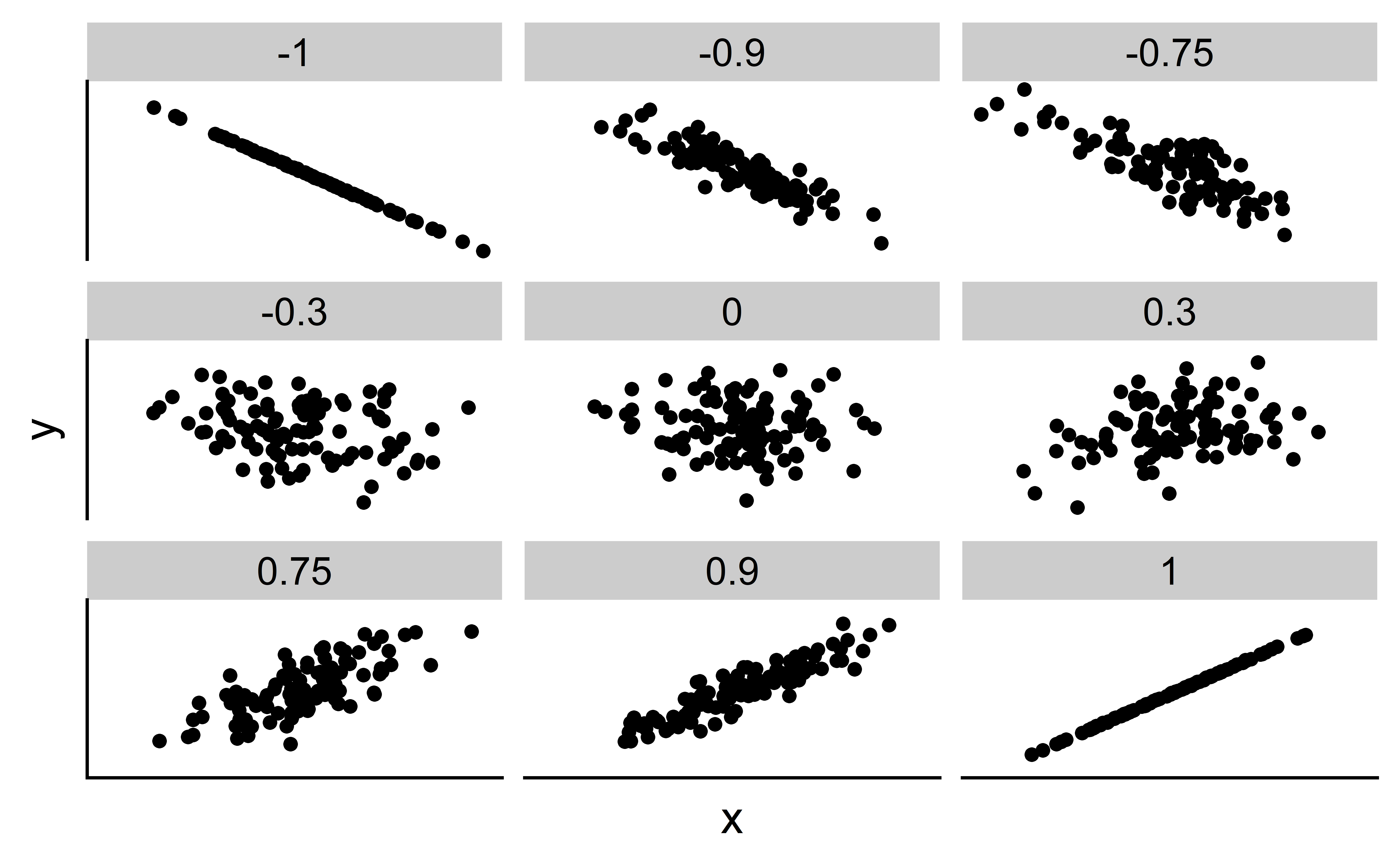
A Figura 1 apresenta exemplos de 9 diferentes valores de coeficientes de correlação para variáveis numéricas hipotéticas \(x\) e \(y\). Por exemplo, observe no gráfico superior direito que, para um coeficiente de correlação de -0.75, existe uma relação linear negativa entre \(x\) e \(y\), mas ela não é tão forte quanto a relação linear negativa entre \(x\) e \(y\) quando o coeficiente de correlação é -0.9 ou -1.
O coeficiente de correlação pode ser calculado usando a função cor() com a função summarize().
# A tibble: 1 × 1
correlação
<dbl>
1 0.187No nosso caso, o coeficiente de correlação de 0.187 indica que a relação entre a nota de avaliação do ensino e a média de “beleza” é positiva e fraca. Existe uma certa subjetividade na interpretação dos coeficientes de correlação, especialmente aqueles que não estão próximos dos valores extremos de -1, 0 e 1. Para desenvolver sua intuição sobre coeficientes de correlação, jogue o jogo de video game estilo anos 1980 “Adivinhe a Correlação”, mencionado na subseção Seção 5.4.1.
Vamos agora realizar o último dos passos em uma ADE: criar visualizações dos dados. Como as variáveis score e bty_avg são numéricas, um gráfico de dispersão é apropriado para visualizar a relação entre elas. Vamos fazer isso usando geom_point() e exibir o resultado na Figura 2. Além disso, vamos destacar os seis pontos no canto superior direito da visualização em uma caixa.
margin_x <- 0.15
margin_y <- 0.075
box <- tibble(
x = c(7.83, 8.17, 8.17, 7.83, 7.83) + c(-1, 1, 1, -1, -1) * margin_x,
y = c(4.6, 4.6, 5, 5, 4.6) + c(-1, -1, 1, 1, -1) * margin_y
)
evals_ch5 |>
ggplot(aes(bty_avg,score)) +
geom_point(alpha = 0.15) +
geom_path(data = box, aes(x = x, y = y),
col = "red", linewidth = 1) +
labs(
x = "Pontuação de beleza",
y = "Pontuação de ensino",
title = "Gráfico de dispersão sobre a relação entre \nas pontuações de ensino e beleza"
)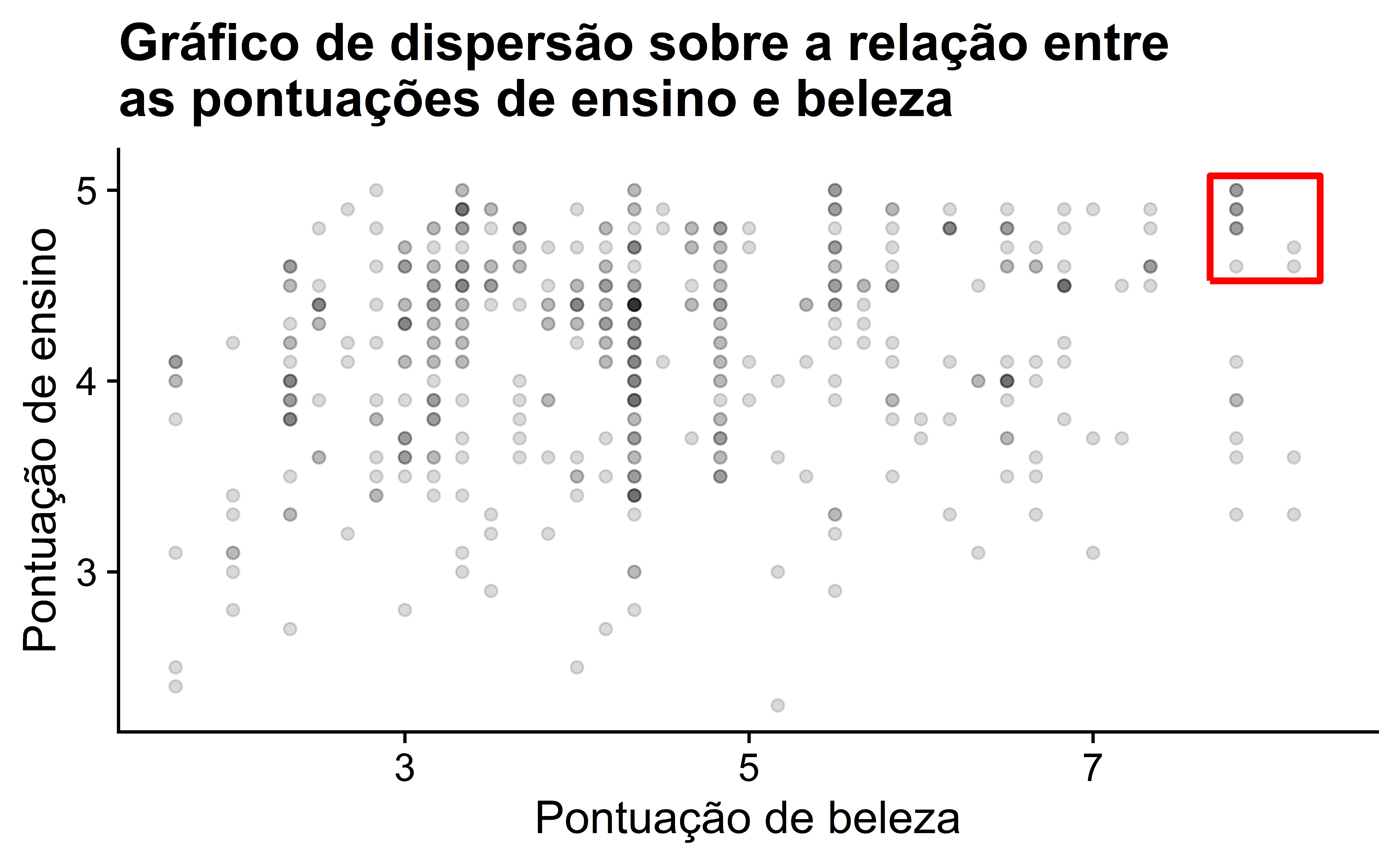
Observe que a maioria das pontuações de “beleza” fica entre 2 e 8, enquanto a maioria das notas de ensino fica entre 3 e 5. Embora as opiniões possam variar, acreditamos que a relação entre a nota de ensino e a pontuação de “beleza” é fraca e positiva. Isso é consistente com nosso coeficiente de correlação calculado anteriormente de 0.187.
Além disso, parece haver seis pontos no canto superior direito deste gráfico destacados na caixa. No entanto, isso não é realmente o caso, pois este gráfico sofre de sobreposição. Lembre-se da Subseção 2.3.2 que a sobreposição ocorre quando vários pontos estão empilhados diretamente uns sobre os outros, tornando difícil distingui-los. Então, embora possa parecer que há apenas seis pontos na caixa, na verdade há mais. Esse fato só fica aparente ao usar geom_jitter() no lugar de geom_point(). Exibimos o gráfico resultante na Figura 3 junto com a mesma pequena caixa da Figura 2.
evals_ch5 |>
ggplot(aes(bty_avg,score)) +
geom_jitter(alpha = 0.15) +
labs(
x = "Pontuação de beleza",
y = "Pontuação de ensino",
title = "Gráfico de dispersão sobre as relações entre \nas pontuações de ensino e beleza (com jitter)"
) +
geom_path(data = box, aes(x = x, y = y), col = "red", linewidth = 1)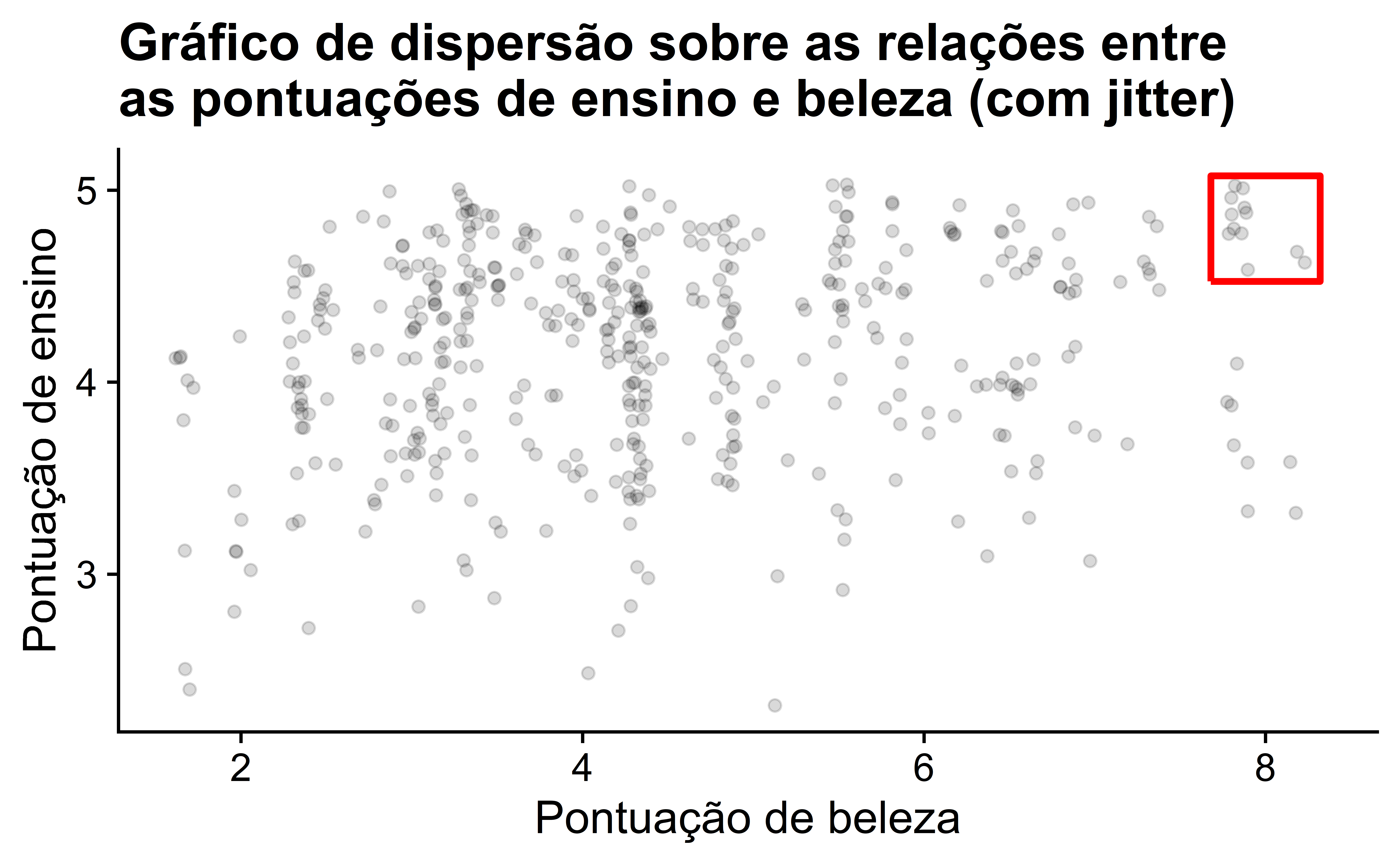
Agora está claro que há 12 pontos na área destacada na caixa e não seis, como originalmente sugerido na Figura 2. Lembre-se da Subseção 2.3.2, sobre sobreposição, que o jittering adiciona um pequeno “empurrão” aleatório a cada um dos pontos para desfazer essas sobreposições. Além disso, lembre-se de que o jittering é estritamente uma ferramenta de visualização; ele não altera os valores originais no banco de dados evals_ch5. No entanto, para simplificar daqui para frente, apresentaremos apenas gráficos de dispersão regulares em vez de suas versões com jittering.
Vamos aprimorar o gráfico de dispersão sem jitter da Figura 2 adicionando uma linha de “melhor ajuste”: de todas as possíveis linhas que podemos desenhar neste gráfico, é a linha que melhor se ajusta à nuvem de pontos. Fazemos isso adicionando uma nova camada geom_smooth(method = "lm", se = FALSE) ao código ggplot() que criou o gráfico de dispersão na Figura 2. O argumento method = "lm" define a linha como um “modelo linear”. O argumento se = FALSE suprime as barras de visualização dos intervalos de confiança do erro padrão (Definiremos o conceito de erro padrão mais tarde na Subseção 7.3.2.).
evals_ch5 |>
ggplot(aes(bty_avg,score, alpha = 0.1)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE,
color = "black") +
labs(
x = "Pontuação de beleza",
y = "Pontuação de ensino",
title = "Gráfico de dispersão sobre as relações entre \nas pontuações de ensino e beleza",
) +
theme(
legend.position = "none"
)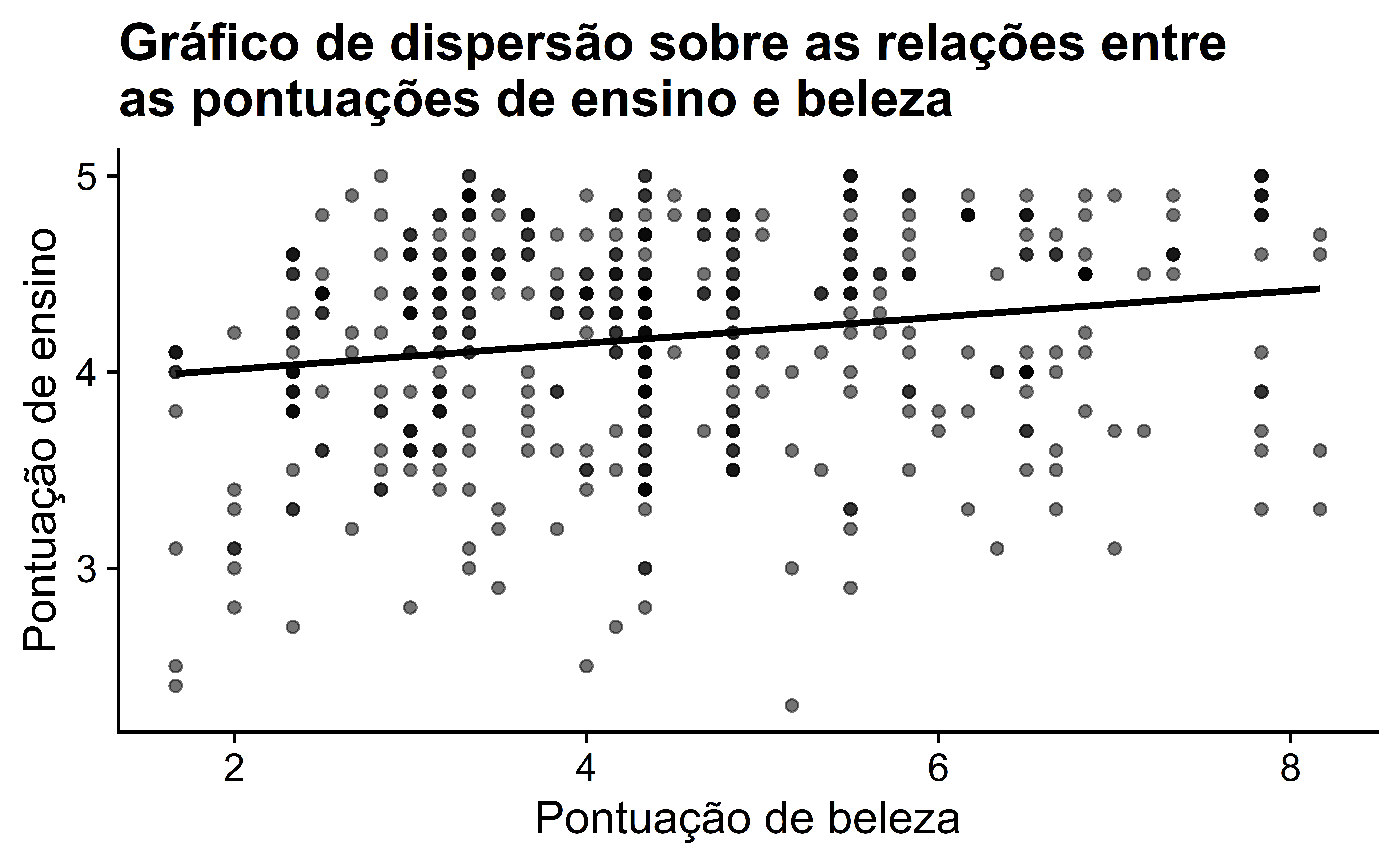
A linha no resultado da Figura 4 é chamada de “linha de regressão”. A linha de regressão é um resumo visual da relação entre duas variáveis numéricas, no nosso caso a variável de resultado score e a variável explicativa bty_avg. A inclinação positiva da linha azul é consistente com nosso coeficiente de correlação observado anteriormente de 0.187, sugerindo que existe uma relação positiva entre essas duas variáveis: à medida que os instrutores têm pontuações de “beleza” mais altas, eles também recebem avaliações de ensino mais altas. Veremos mais tarde, no entanto, que enquanto o coeficiente de correlação e a inclinação de uma linha de regressão sempre têm o mesmo sinal (positivo ou negativo), eles tipicamente não têm o mesmo valor.
Uma linha de regressão é “melhor ajustada” no sentido de que minimiza alguns critérios matemáticos. Apresentamos esses critérios matemáticos na Subseção 5.3.2, mas sugerimos que você leia esta subseção apenas depois de ler primeiro o resto desta seção sobre regressão com uma variável explicativa numérica.
Realize uma nova análise exploratória de dados com a mesma variável de resultado \(y\) sendo score, mas com age como a nova variável explicativa \(x\). Lembre-se, isso envolve três coisas:
- Olhar os valores brutos dos dados.
- Calcular estatísticas descritivas.
- Criar visualizações de dados.
Com base nesta exploração, o que você pode dizer sobre a relação entre idade e pontuações de ensino?
5.1.2 Regressão linear simples
Você pode se lembrar da álgebra do ensino médio que a equação de uma linha é \(y = a + b \cdot x\).2 Ela é definida por dois coeficientes \(a\) e \(b\). O coeficiente de interceptação \(a\) é o valor de \(y\) quando \(x = 0\). O coeficiente de inclinação \(b\) para \(x\) é o aumento em \(y\) para cada aumento de um ponto em \(x\). Isso também é chamado de “taxa de variação”. É possível visualizar essa relação na Figura 5, onde \(a\) é igual a 2 e \(b\) é igual a 3 (\(y = 2 + 3 \cdot x\))
# A tibble: 5 × 2
x y
<dbl> <dbl>
1 0 2
2 1 5
3 2 8
4 3 11
5 4 14reg_line |>
ggplot(aes(x,y)) +
geom_smooth(
method = "lm", se = F,
color = "blue"
) +
geom_point(
color = "red",size = 2
) +
geom_segment(aes(xend = x, yend = 0),
linetype = "dashed",
color = "black") +
geom_segment(aes(xend = 0, yend = y),
linetype = "dashed",
color = "black") +
scale_y_continuous(breaks = c(2, 5, 8, 11, 14)) +
scale_color_colorblind()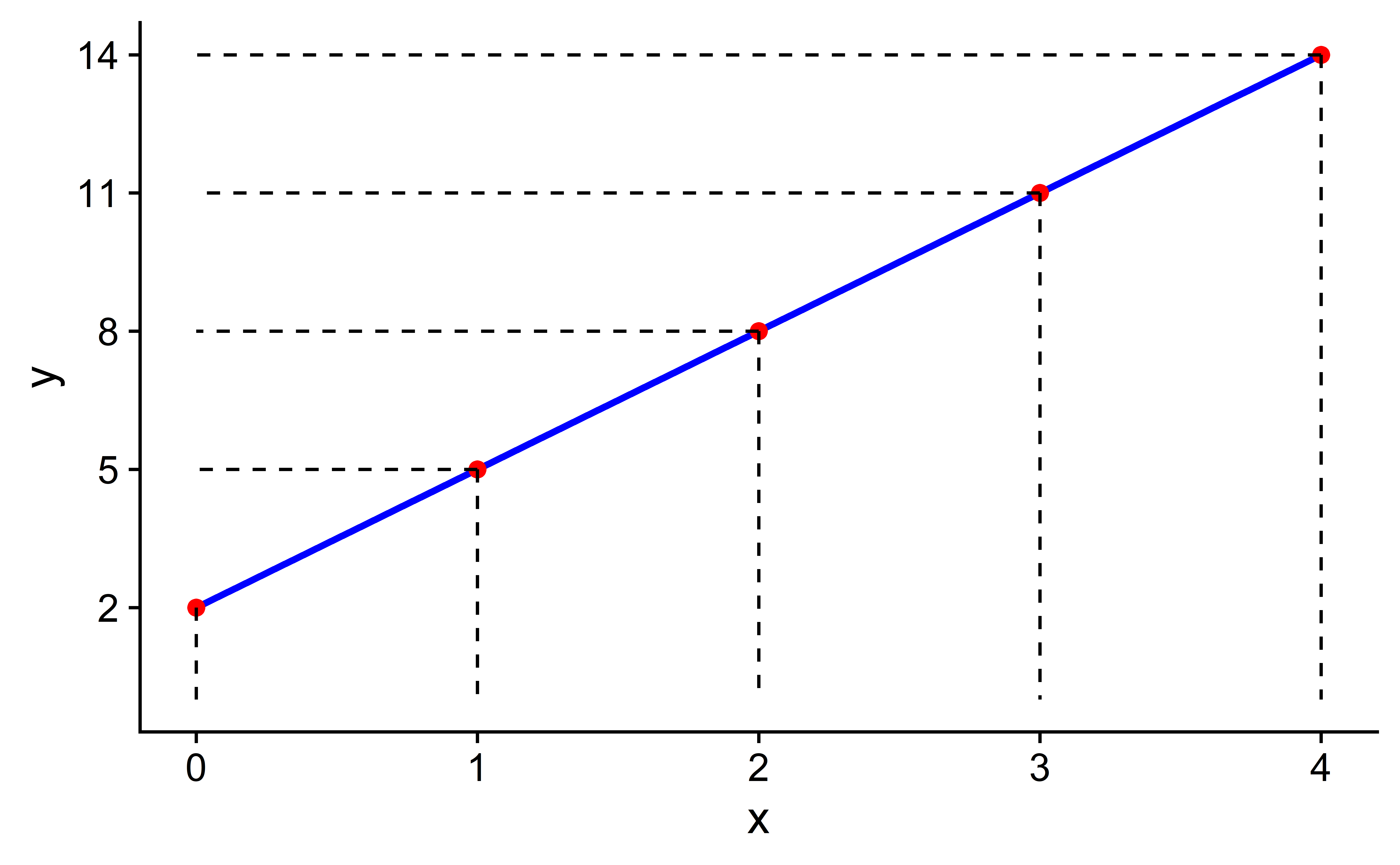
No entanto, ao definir uma linha de regressão, como na Figura 4, usamos uma notação ligeiramente diferente: a equação da linha de regressão é \(\hat{y} = b_0 + b_1 \cdot x\). O coeficiente de interceptação é \(b_0\), então \(b_0\) é o valor de \(\hat{y}\) quando \(x = 0\). O coeficiente de inclinação para \(x\) é \(b_1\), ou seja, o aumento em \(\hat{y}\) para cada aumento de um em \(x\). Por que colocamos um “chapéu” (acento circunflexo) em cima do \(y\)? É uma forma de notação comumente usada em regressão para indicar que temos um “valor ajustado”, ou o valor de \(y\) na linha de regressão para um dado valor de \(x\). Discutiremos isso mais na próxima Subseção 5.1.3.
Sabemos que a linha de regressão na Figura 4 tem uma inclinação positiva \(b_1\) correspondente à nossa variável explicativa \(x\) bty_avg. Por quê? Porque à medida que os instrutores tendem a ter pontuações bty_avg mais altas, eles também tendem a ter pontuações de avaliação de ensino mais altas. No entanto, qual é o valor numérico da inclinação \(b_1\)? E quanto ao intercepto \(b_0\)? Não vamos calcular esses dois valores à mão, mas sim usar um computador!
Podemos obter os valores do intercepto \(b_0\) e a inclinação para bty_avg \(b_1\) exibindo uma tabela de regressão linear. Isso é feito em duas etapas:
- Primeiro, “ajustamos” o modelo de regressão linear usando a função
lm()e o salvamos emscore_model. - Obtemos a tabela de regressão aplicando a função tidy() do pacote
broomemscore_model.
# Ajuste o modelo de regressão:
score_model <- lm(score ~ bty_avg, data = evals_ch5)
# Obtenha a tabela de regressão:
score_model |>
tidy(conf.int = T) |>
mutate(
across(where(is.double),
\(x) round(x, 3))
)# A tibble: 2 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 3.88 0.076 51.0 0 3.73 4.03
2 bty_avg 0.067 0.016 4.09 0 0.035 0.099Podemos melhorar essa visualização utilizando uma tabela:
score_model |>
tidy(conf.int = T) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = everything()
) |>
fmt_number(
decimals = 3,
)| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 3.880 | 0.076 | 50.961 | 0.000 | 3.731 | 4.030 |
| bty_avg | 0.067 | 0.016 | 4.090 | 0.000 | 0.035 | 0.099 |
Vamos primeiro focar em interpretar a saída da tabela de regressão na Tabela 2. Na coluna de estimativa da Tabela 2 estão o intercepto \(b_0 = 3.88\) e a inclinação \(b_1 = 0.067\) para bty_avg. Assim, a equação da linha de regressão na Figura 4 é a seguinte:
\[ \begin{aligned} \widehat{y} &= b_0 + b_1 \cdot x\\ \widehat{\text{score}} &= b_0 + b_{\text{bty}\_\text{avg}} \cdot\text{bty}\_\text{avg}\\ &= 3.88 + 0.067\cdot\text{bty}\_\text{avg} \end{aligned} \]
O intercepto \(b_0 = 3.88\) é a nota média de ensino \(\hat{y} = \widehat{score}\) para aqueles cursos onde o instrutor tinha uma pontuação de “beleza” bty_avg de 0. Ou, em termos gráficos, é onde a linha intercepta o eixo \(y\) quando \(x = 0\). No entanto, observe que, embora o intercepto da linha de regressão tenha uma interpretação matemática, ele não tem uma interpretação prática aqui, já que observar um bty_avg de 0 é impossível; ele é a média das pontuações de “beleza” de seis avaliadores, variando de 1 a 10. Além disso, olhando para o gráfico de dispersão com a linha de regressão na Figura 4, nenhum instrutor tinha uma pontuação de “beleza” próxima de 0.
O mais importante é a inclinação \(b_1 = b_{bty\_avg}\) para bty_avg de 0.067, pois isso resume a relação entre as variáveis de pontuação de ensino e “beleza”. Observe que o sinal é positivo, sugerindo uma relação positiva entre essas duas variáveis, o que significa que professores com pontuações de “beleza” mais altas também tendem a ter pontuações de ensino mais altas. Lembre-se de que, anteriormente, o coeficiente de correlação era 0.187. Ambos têm o mesmo sinal positivo, mas têm um valor diferente. Lembre-se ainda que a interpretação da correlação é a “força da associação linear”. A interpretação da inclinação é um pouco diferente:
Para cada aumento de 1 unidade em
bty_avg, há um aumento associado de, em média, 0.067 unidades emscore.
Afirmamos apenas que existe um aumento associado e não necessariamente um aumento causal. Por exemplo, talvez pontuações de “beleza” mais altas não causem diretamente pontuações de ensino mais altas. Em vez disso, o seguinte pode ser verdadeiro: indivíduos de origens mais ricas tendem a ter formações educacionais mais fortes e, portanto, têm pontuações de ensino mais altas, enquanto ao mesmo tempo esses indivíduos ricos também tendem a ter pontuações de “beleza” mais altas. Em outras palavras, apenas porque duas variáveis estão fortemente associadas, isso não significa necessariamente que uma cause a outra. Isso é resumido na frase frequentemente citada, “correlação não é necessariamente causalidade”. Discutimos essa ideia mais adiante na Subseção Seção 5.3.1
Além disso, dizemos que esse aumento associado é, em média, de 0.067 unidades na pontuação de ensino, porque você pode ter dois instrutores cujas pontuações bty_avg diferem por 1 unidade, mas a diferença em suas pontuações de ensino não será necessariamente exatamente 0.067. O que a inclinação de 0.067 está dizendo é que, em todos os cursos possíveis, a diferença média na pontuação de ensino entre dois instrutores cujas pontuações de “beleza” diferem por um é de 0.067.
Agora que aprendemos a calcular a equação para a linha de regressão na Figura 4 usando os valores na coluna de estimativa da Tabela 2 e como interpretar o intercepto e a inclinação resultantes, vamos revisitar o código que gerou essa tabela:
Primeiro, “ajustamos” o modelo de regressão linear aos dados usando a função lm() e salvamos isso como score_model. Quando dizemos “ajustar”, queremos dizer “encontrar a melhor linha de ajuste para esses dados”. lm() significa “linear model (modelo linear)” e é usado da seguinte maneira: lm(y ~ x, data = nome_do_banco_de_dados), onde:
-
yé a variável de resultado, seguida de um til~. No nosso caso,yé definido comoscore. -
xé a variável explicativa. No nosso caso,xé definido comobty_avg. - A combinação de
y ~ xé chamada de fórmula do modelo. (Note a ordem deyex). No nosso caso, a fórmula do modelo éscore ~ bty_avg. -
nome_do_banco_de_dadosé o nome do banco de dados que contém as variáveisyex. No nosso caso,nome_do_banco_de_dadosé o banco de dadosevals_ch5.
Segundo, pegamos o modelo salvo em score_model e aplicamos a função tidy() do pacote broom para obter a tabela de regressão na Tabela 2.
Por último, você pode estar se perguntando o que são as cinco colunas restantes na Tabela 2: std_error, statistic, p_value, lower_ci e upper_ci. São o erro padrão, estatística do teste, valor-p, limite inferior do intervalo de confiança de 95% e limite superior do intervalo de confiança de 95%. Eles nos informam sobre a significância estatística e prática dos nossos resultados. Isso é vagamente a “significância” dos nossos resultados de uma perspectiva estatística. Vamos deixar de lado essas ideias por enquanto e revisitá-las no Capítulo 10 sobre inferência (estatística) para regressão. Faremos isso depois de ter a chance de cobrir erros padrão no Capítulo 7, intervalos de confiança no Capítulo 8 e testes de hipótese e valores-p no Capítulo 9.
Ajuste uma nova regressão linear simples usando lm(score ~ age, data = evals_ch5), onde age (idade) é a nova variável explicativa $x$. Obtenha informações sobre a linha de “melhor ajuste” da tabela de regressão aplicando a função tidy(). Como os resultados da regressão se alinham com os resultados de sua análise exploratória de dados anterior?
5.1.3 Valores observados/ajustados e resíduos
Acabamos de ver como obter o valor do intercepto e da inclinação de uma linha de regressão a partir da coluna de estimativa de uma tabela de regressão gerada pela função tidy(). Agora, digamos que queremos informações sobre observações individuais. Por exemplo, vamos nos concentrar no 21º dos 463 cursos no banco de dados evals_ch5 na Tabela 3:
evals_ch5 |>
slice(21)# A tibble: 1 × 4
id score bty_avg age
<int> <dbl> <dbl> <int>
1 21 4.9 7.33 31E vamos colocar esse dados em uma tabela:
evals_ch5 |>
slice(21) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = everything()
) |>
fmt_number(
decimals = 1,
columns = c(score, bty_avg)
)| id | score | bty_avg | age |
|---|---|---|---|
| 21 | 4.9 | 7.3 | 31 |
Qual é o valor \(\hat{y}\) na linha de regressão correspondente à pontuação de “beleza” bty_avg de 7.3 deste instrutor? Na Figura 6, marcamos três valores correspondentes ao instrutor deste 21º curso e damos seus nomes estatísticos:
- Círculo: O valor observado \(y = 4.9\) é a nota de ensino real do instrutor deste curso.
- Quadrado: O valor ajustado \(\hat{y}\) é o valor na linha de regressão para \(x = bty\_avg = 7.333\). Este valor é calculado usando o intercepto e a inclinação da tabela de regressão anterior:
\[ \hat{y} = b_0 + b_1 \cdot x = 3.88 + 0.067 \cdot 7.333 = 4.369 \]
- Seta: O comprimento desta seta é o resíduo e é calculado subtraindo o valor ajustado \(\hat{y}\) do valor observado \(y\). O resíduo pode ser pensado como um erro do modelo ou “falta de ajuste” para uma observação específica. No caso do instrutor deste curso, é $y - = 4.9 - 4.369 = 0.531.
evals_ch5 |>
ggplot(aes(bty_avg,score, alpha = 0.1)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE,
color = "black") +
annotate("point", x = eixo_x, y = circulo,
col = "red", shape = 20,
size = 4) +
annotate("point", x = eixo_x, y = quadrado,
col = "red", shape = 15,
size = 3) +
annotate("segment", x = eixo_x, xend = eixo_x,
y = circulo, yend = quadrado, color = "blue",
arrow = arrow(type = "closed", length = unit(0.02, "npc")))+
theme(
legend.position = "none"
) +
labs(
x = "Pontuação de beleza",
y = "Pontuação de ensino",
title = "Relação entre as pontuações de ensino e beleza"
) +
scale_color_colorblind()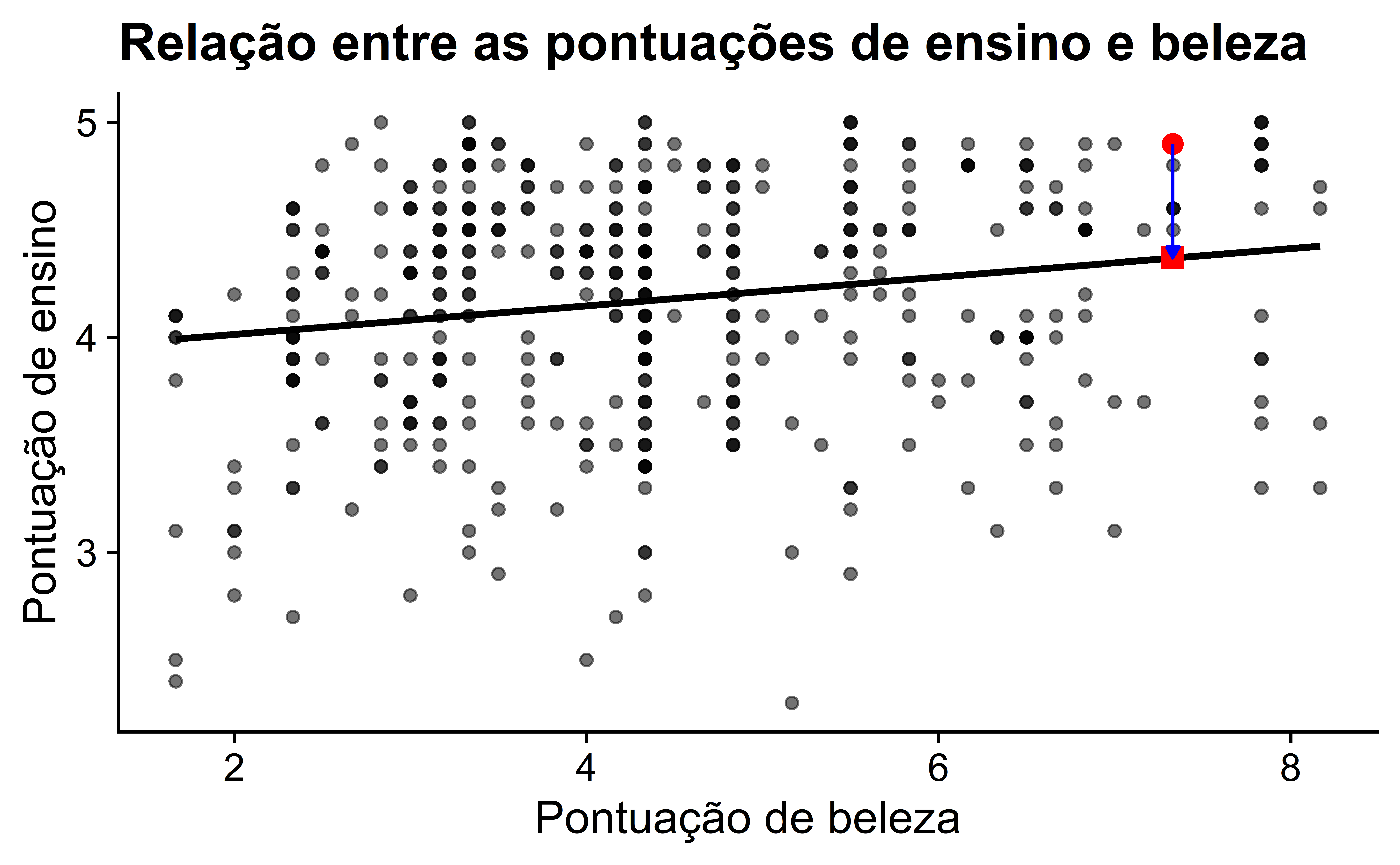
Agora, digamos que queremos calcular tanto o valor ajustado \(\hat{y} = b_0 + b_1 \cdot x\) quanto o resíduo \(y - \hat{y}\) para todos os 463 cursos no estudo. Lembre-se de que cada curso corresponde a uma das 463 linhas no banco de dados evals_ch5 e também a um dos 463 pontos no gráfico de regressão na Figura 6.
Poderíamos repetir os cálculos anteriores que fizemos à mão 463 vezes, mas isso seria tedioso e demorado. Em vez disso, vamos fazer isso usando um computador com a função augment(), que recebe um objeto contendo um modelo e um banco de dados e adiciona informações para cada caso. Aqui, estamos interssados, em particular, nos valores ajustados e nos resíduos. Vamos aplicar a função augment() ao score_model, que é onde salvamos nosso modelo lm() na seção anterior. Na Tabela 4, apresentamos os resultados apenas dos cursos de 21º a 24º, por uma questão de brevidade.
# A tibble: 4 × 10
id score bty_avg age .fitted .resid .hat .sigma .cooksd .std.resid
<int> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 21 4.9 7.33 31 4.37 0.531 0.0100 0.535 0.00505 0.998
2 22 4.6 7.33 31 4.37 0.231 0.0100 0.535 0.000956 0.434
3 23 4.5 7.33 31 4.37 0.131 0.0100 0.535 0.000308 0.246
4 24 4.4 5.5 62 4.25 0.153 0.00325 0.535 0.000134 0.287Vamos colocar esse dados em uma tabela e, por enquanto, não vamos tratar das colunas .hat .sigma, .cooksd e .std.resid. Também excluiremos a coluna age (idade), pois não a estamos utilizando nessa análise:
score_model |>
augment(evals_ch5) |>
select(id:.resid, -age) |>
slice(21:24) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = everything()
) |>
fmt_number(
decimals = 2,
columns = c(score:.resid)
)| id | score | bty_avg | .fitted | .resid |
|---|---|---|---|---|
| 21 | 4.90 | 7.33 | 4.37 | 0.53 |
| 22 | 4.60 | 7.33 | 4.37 | 0.23 |
| 23 | 4.50 | 7.33 | 4.37 | 0.13 |
| 24 | 4.40 | 5.50 | 4.25 | 0.15 |
Vamos inspecionar as colunas individuais e relacioná-las com os elementos da Figura 6:
- A coluna
scorerepresenta a variável de resultado observada \(y\). Esta é a posição y dos 463 pontos pretos. - A coluna
bty_avgrepresenta os valores da variável explicativa \(x\). Esta é a posição x dos 463 pontos pretos. - A coluna
.fittedrepresenta os valores ajustados \(\hat{y}\). Este é o valor correspondente na linha de regressão para os 463 valores de \(x\). - A coluna
.residrepresenta os resíduos \(y - \hat{y}\). Estas são as 463 distâncias verticais entre os 463 pontos pretos e a linha de regressão.
Assim como fizemos para o instrutor do 21º curso no banco de dados evals_ch5 (na primeira linha da tabela), vamos repetir os cálculos para o instrutor do 24º curso (na quarta linha da Tabela 4):
-
score\(= 4.4\) é a nota de ensino observada \(y\) para o instrutor deste curso. -
bty_avg\(= 5.50\) é o valor da variável explicativabty_avg\(x\) para o instrutor deste curso. -
.fitted= \(4.25 = 3.88 + 0.067 \cdot 5.50\) é o valor ajustado \(\hat{y}\) na linha de regressão para o instrutor deste curso. -
.resid\(= 0.15 = 4.40 - 4.25\) é o valor do resíduo para este instrutor. Em outras palavras, o valor ajustado do modelo estava errado por 0.15 unidades de pontuação de ensino para o instrutor deste curso.
Neste ponto, você pode avançar, se desejar, para a Subseção 5.3.2 para aprender sobre os processos por trás do que torna as linhas de regressão “melhor ajustadas”. Como uma introdução, uma linha “melhor ajustada” refere-se à linha que minimiza a soma dos resíduos quadrados de todas as linhas possíveis que podemos desenhar através dos pontos. Na Seção 5.2, discutiremos outro cenário comum de ter uma variável explicativa categórica e uma variável de resultado numérica.
Gere um banco de dados dos resíduos do modelo no qual você usou age (idade) como a variável explicativa \(x\).
5.2 Uma variável explicativa categórica
É uma verdade infeliz que a expectativa de vida não é a mesma em todos os países do mundo. Agências de desenvolvimento internacional estão interessadas em estudar essas diferenças na expectativa de vida com a esperança de identificar onde os governos devem alocar recursos para abordar esse problema. Nesta seção, exploraremos as diferenças na expectativa de vida de duas maneiras:
- Diferenças entre continentes: Existem diferenças significativas na expectativa de vida média entre os cinco continentes habitados do mundo: África, Américas, Ásia, Europa e Oceania?
- Diferenças dentro dos continentes: Como a expectativa de vida varia dentro dos cinco continentes do mundo? Por exemplo, a dispersão da expectativa de vida entre os países da África é maior do que a dispersão da expectativa de vida entre os países da Ásia?
Para responder a essas perguntas, usaremos o banco de dados gapminder incluído no pacote gapminder. Este conjunto de dados possui estatísticas de desenvolvimento internacional, como expectativa de vida, PIB per capita e população para 142 países em intervalos de 5 anos entre 1952 e 2007. Lembre-se de que visualizamos alguns desses dados na Figura 2.1 na Subseção 2.1.2 sobre a gramática dos gráficos.
Usaremos esses dados para regressão básica novamente, mas agora usando uma variável explicativa \(x\) que é categórica, ao contrário do modelo de variável explicativa numérica que usamos na Seção 5.1 anterior.
- Uma variável de resultado numérica \(y\) (a expectativa de vida de um país) e
- Uma única variável explicativa categórica \(x\) (o continente ao qual o país pertence).
Quando a variável explicativa \(x\) é categórica, o conceito de uma linha de regressão “melhor ajustada” é um pouco diferente do que vimos anteriormente na Seção 5.1, onde a variável explicativa \(x\) era numérica. Estudaremos essas diferenças em breve na Subseção 5.2.2, mas primeiro realizamos uma análise de dados exploratória.
5.2.1 Análise de dados exploratória
Os dados dos 142 países estão disponíveis no banco de dados gapminder, incluído no pacote gapminder. No entanto, para simplificar, vamos usar a função filter() para selecionar apenas aquelas observações/linhas correspondentes ao ano de 2007. Adicionalmente, vamos utilizar a função select() para escolher apenas o subconjunto de variáveis que consideraremos neste capítulo. Salvaremos esses dados em um novo banco de dados chamado gapminder2007:
library(gapminder)
gapminder2007 <- gapminder |>
filter(year == 2007) |>
select(country, lifeExp, continent, gdpPercap) |>
clean_names()Vamos realizar o primeiro passo usual em uma análise exploratória de dados: olhar os valores brutos dos dados. Você pode fazer isso usando o visualizador de planilhas do RStudio ou utilizando o comando glimpse(), como introduzido na Subseção 1.4.3 sobre a exploração de bancos de dados:
gapminder2007 |>
glimpse()Rows: 142
Columns: 4
$ country <fct> "Afghanistan", "Albania", "Algeria", "Angola", "Argentina",…
$ life_exp <dbl> 43.828, 76.423, 72.301, 42.731, 75.320, 81.235, 79.829, 75.…
$ continent <fct> Asia, Europe, Africa, Africa, Americas, Oceania, Europe, As…
$ gdp_percap <dbl> 974.5803, 5937.0295, 6223.3675, 4797.2313, 12779.3796, 3443…Observe que Rows: 142 indica que existem 142 linhas/observações em gapminder2007, onde cada linha corresponde a um país. Em outras palavras, a unidade de observação é um país individual. Além disso, observe que a variável continent é do tipo <fct>, que significa fator, que é a maneira do R de codificar variáveis categóricas.
Uma descrição completa de todas as variáveis incluídas em gapminder pode ser encontrada lendo o arquivo de ajuda associado (execute ?gapminder no console). No entanto, vamos descrever completamente apenas as 4 variáveis que selecionamos em gapminder2007:
-
country: Uma variável de identificação do tipo caractere/texto usada para distinguir os 142 países no banco de dados. -
lifeexp: Uma variável numérica da expectativa de vida ao nascer desse país. Esta é a variável de resultado \(y\) de interesse. -
continent: Uma variável categórica com cinco níveis. Aqui, “níveis” correspondem às possíveis categorias: África, Ásia, Américas, Europa e Oceania. Esta é a variável explicativa \(x\) de interesse. -
gdppercap: Uma variável numérica do PIB per capita desse país em dólares americanos ajustados pela inflação que usaremos como outra variável de resultado \(y\) na verificação do aprendizado no final desta subseção.
Vamos olhar uma amostra aleatória de cinco dos 142 países na Tabela 5.
set.seed(76)
gapminder2007 |>
slice_sample(n = 5) |>
gt() |>
cols_align(
align = c("center"),
columns = c(!country)
) |>
cols_align(
align = c("left"),
columns = c(country)
) |>
fmt_number(
decimals = 1,
columns = c(life_exp, gdp_percap)
) |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
tab_style(
style = list(
cell_text(align = "center")
),
locations = cells_column_labels(
columns = country
)
)| country | life_exp | continent | gdp_percap |
|---|---|---|---|
| Togo | 58.4 | Africa | 883.0 |
| Sao Tome and Principe | 65.5 | Africa | 1,598.4 |
| Congo, Dem. Rep. | 46.5 | Africa | 277.6 |
| Lesotho | 42.6 | Africa | 1,569.3 |
| Bulgaria | 73.0 | Europe | 10,680.8 |
Observe que a amostragem aleatória provavelmente produzirá um subconjunto diferente de 5 linhas para você do que o mostrado. Para evitar isso, usamos novamente a função set.seed() Agora que olhamos os valores brutos no nosso banco de dados gapminder2007 e obtivemos uma noção dos dados, passemos para o cálculo de estatísticas descritivas. Vamos mais uma vez aplicar a função skim() do pacote skimr. Lembre-se da nossa ADE anterior que esta função recebe um banco de dados, o “analisa” e retorna estatísticas descritivas comumente usadas. Vamos pegar nosso banco de dados gapminder2007, selecionar apenas as variáveis de resultado e explicativas, lifeexp e continent, e encaminhá-las para a função skim():
── Data Summary ────────────────────────
Values
Name select(gapminder2007, lif...
Number of rows 142
Number of columns 2
_______________________
Column type frequency:
factor 1
numeric 1
________________________
Group variables None
── Variable type: factor ───────────────────────────────────────────────────────
skim_variable n_missing complete_rate ordered n_unique
1 continent 0 1 FALSE 5
top_counts
1 Afr: 52, Asi: 33, Eur: 30, Ame: 25
── Variable type: numeric ──────────────────────────────────────────────────────
skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100
1 life_exp 0 1 67.0 12.1 39.6 57.2 71.9 76.4 82.6O resultado da função skim() agora relata resumos para variáveis categóricas (Tipo de variável: factor) separadamente das variáveis numéricas (Tipo de variável: numeric). Para a variável categórica continent, ele relata:
-
n_missingecomplete_rate: são o número de valores ausentes e o percentual de valores completos, respectivamente. -
n_unique: O número de níveis únicos desta variável, correspondendo a África, Ásia, Américas, Europa e Oceania. Isso se refere a quantos países estão nos dados para cada continente. -
top_counts: Neste caso, as quatro maiores contagens: África tem 52 países, Ásia tem 33, Europa tem 30 e Américas tem 25. A Oceania, com 2 países, não foi exibida. -
ordered: Isso nos informa se a variável categórica é “ordinal”: se existe uma hierarquia codificada (como baixo, médio, alto). Neste caso,continentnão é ordinal
Voltando nossa atenção para as estatísticas descritivas da variável numérica lifeexp, observamos que a mediana global da expectativa de vida em 2007 era 71.9. Assim, metade dos países do mundo (71 países) tinha uma expectativa de vida inferior a 71.9. No entanto, a expectativa de vida média de 67.0 é mais baixa. Por que a expectativa de vida média é menor que a mediana?
Podemos responder a esta pergunta realizando o último dos três passos comuns em uma ADE: criando visualizações de dados. Vamos visualizar a distribuição da nossa variável de resultado \(y = life\_\exp\) na Figura 7.
gapminder2007 |>
ggplot(aes(life_exp)) +
geom_histogram(binwidth = 5, color = "gray",
fill = "white") +
labs(
x = "Expectativa de vida",
y = "Número de países",
title = "Histograma da distribuição \nda expectativa de vida mundial"
)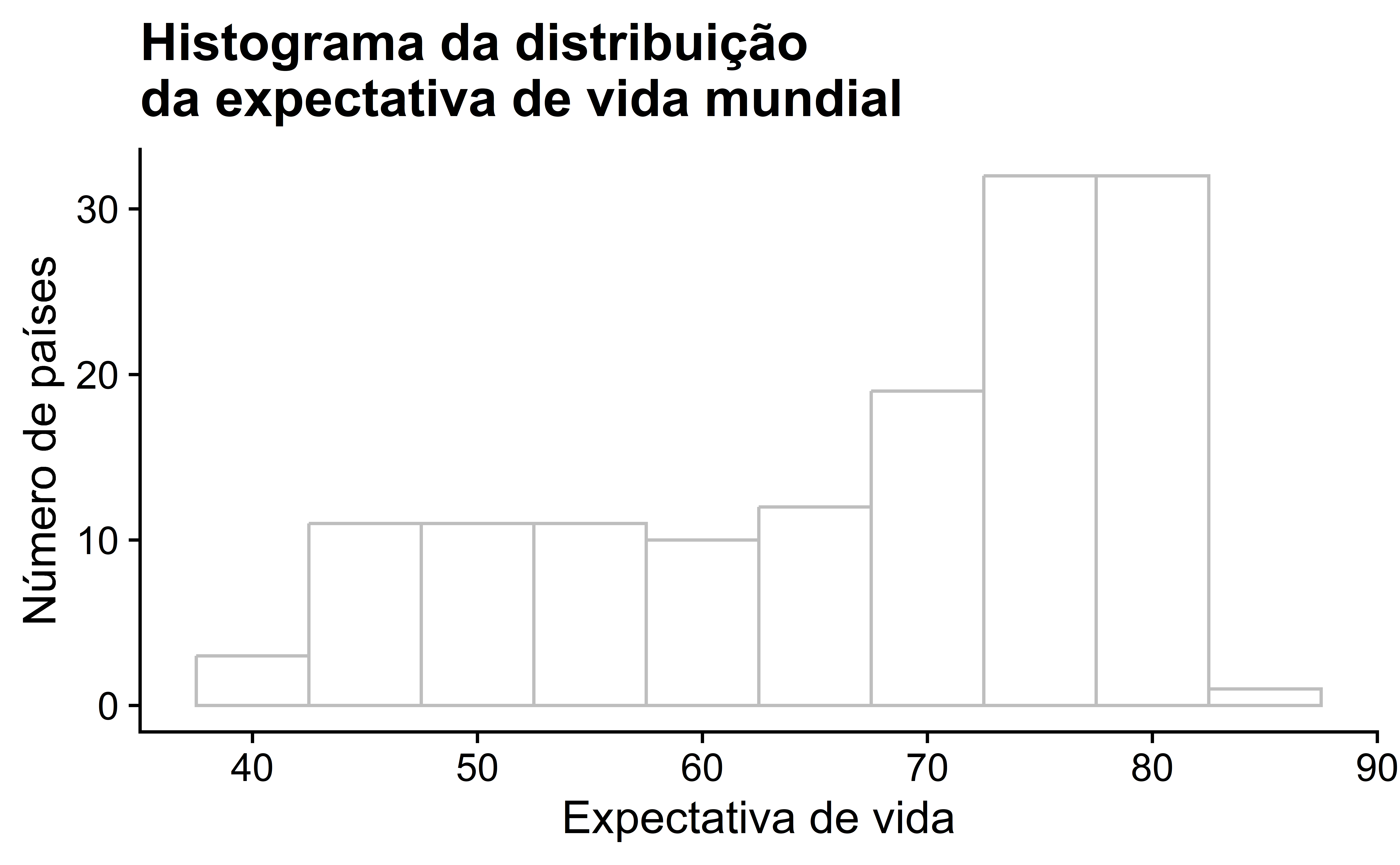
Observamos que esses dados são assimétricos à esquerda, também conhecidos como negativamente assimétricos: há alguns países com baixa expectativa de vida que estão reduzindo a expectativa de vida média. No entanto, a mediana é menos sensível aos efeitos de tais outliers; portanto, a mediana é maior que a média neste caso.
Lembre-se, no entanto, que queremos comparar as expectativas de vida tanto entre continentes quanto dentro dos continentes. Em outras palavras, nossas visualizações precisam incorporar de alguma forma a variável continent. Podemos fazer isso facilmente com um histograma facetado. Lembre-se da Seção 2.6 que as facetas permitem dividir uma visualização pelos diferentes valores de outra variável. Exibimos a visualização resultante na Figura 8, adicionando uma camada facet_wrap(~ continent, nrow = 2).
gapminder2007 |>
ggplot(aes(life_exp)) +
geom_histogram(binwidth = 5, color = "gray",
fill = "white") +
labs(
x = "Expectativa de vida",
y = "Número de países",
title = "Histograma da distribuição da \nexpectativa de vida mundial"
) +
facet_wrap(~ continent, nrow = 2)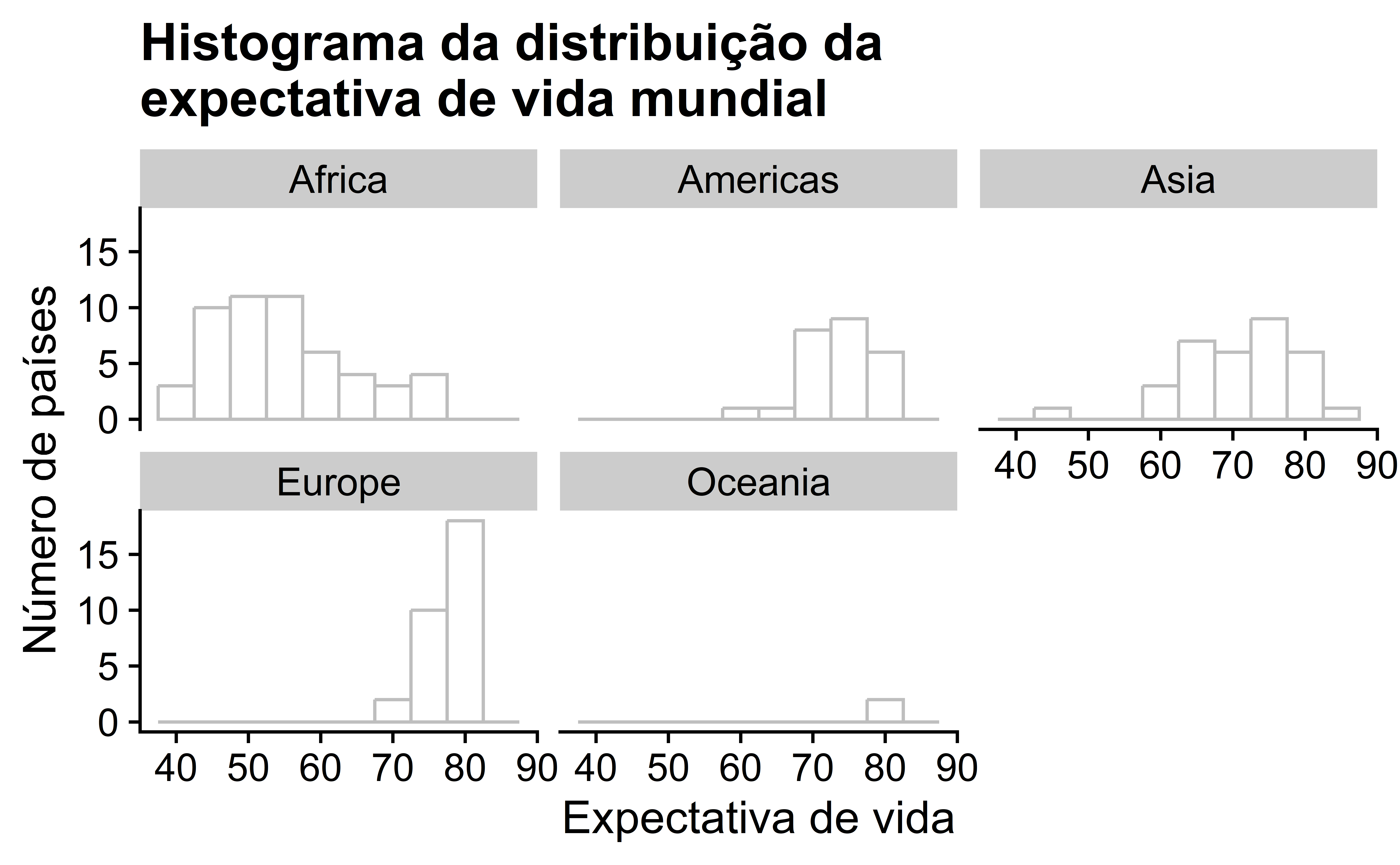
Observe que, infelizmente, a distribuição das expectativas de vida na África é muito mais baixa do que nos outros continentes, enquanto na Europa as expectativas de vida tendem a ser mais altas e, além disso, não variam tanto. Por outro lado, tanto a Ásia quanto a África têm a maior variação nas expectativas de vida. Há a menor variação na Oceania, mas tenha em mente que existem apenas dois países na Oceania: Austrália e Nova Zelândia.
Lembre-se de que um método alternativo para visualizar a distribuição de uma variável numérica dividida por uma variável categórica é usando um boxplot lado a lado. Mapeamos a variável categórica continent para o eixo \(x\) e as diferentes expectativas de vida dentro de cada continente no eixo \(y\) na Figura 9.
gapminder2007 |>
ggplot(aes(fct_reorder(continent, life_exp),
life_exp)) +
geom_boxplot() +
labs(
x = "Continente", y = "Expectativa de vida",
title = "Expectativa de vida por continente"
)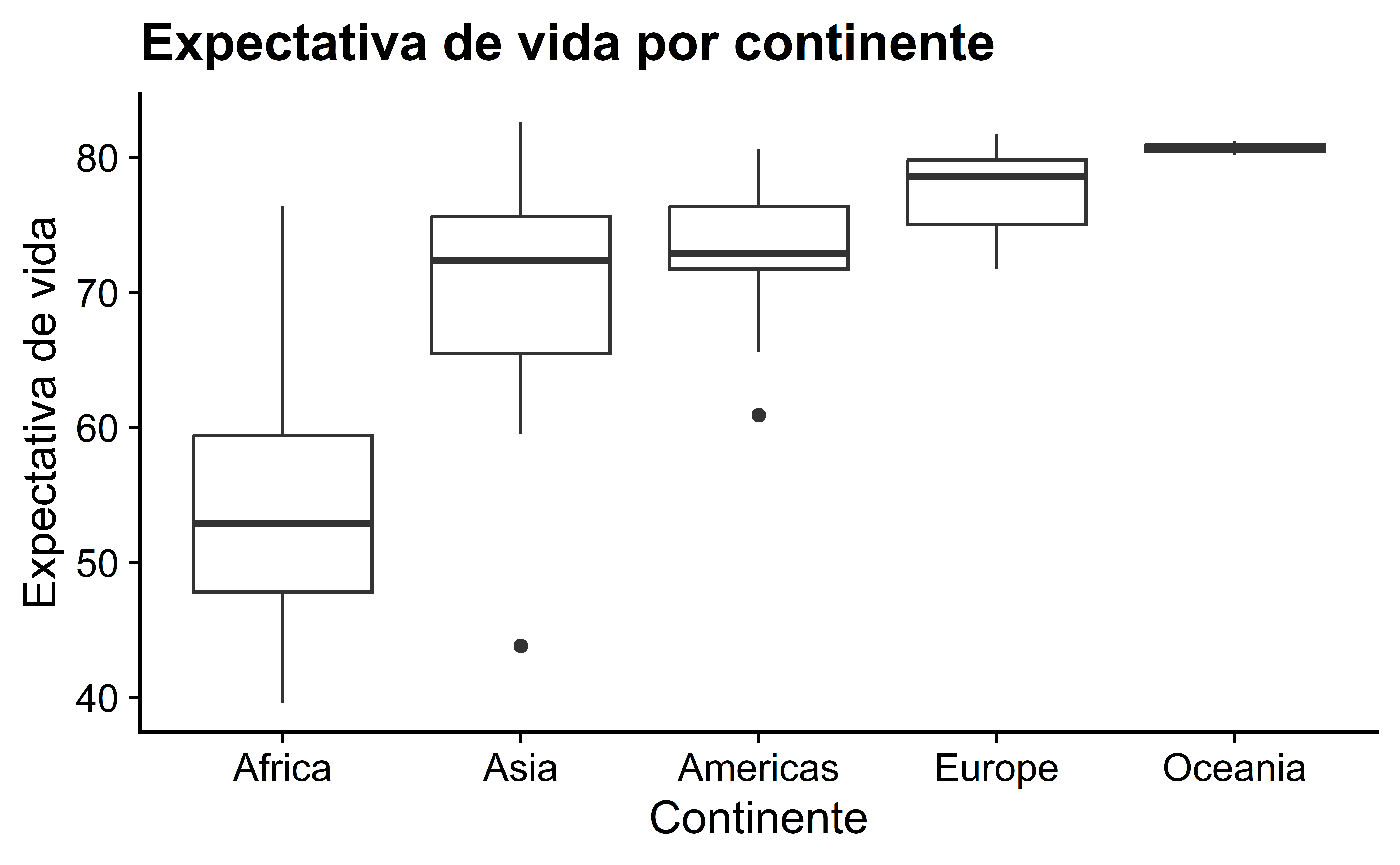
Algumas pessoas preferem comparar as distribuições de uma variável numérica entre diferentes níveis de uma variável categórica usando um boxplot em vez de um histograma facetado. Isso ocorre porque podemos fazer comparações rápidas entre os níveis da variável categórica com linhas horizontais imaginárias. Por exemplo, observe na Figura 9 que podemos rapidamente nos convencer de que a Oceania tem as maiores medianas de expectativa de vida ao desenhar uma linha horizontal imaginária em \(y = 80\). Além disso, como observamos no histograma facetado na Figura 8, a África e a Ásia têm a maior variação na expectativa de vida, conforme evidenciado por seus grandes intervalos interquartis (as alturas das caixas).
É importante lembrar, no entanto, que as linhas sólidas no meio das caixas correspondem às medianas (o valor do meio) e não à média. Então, por exemplo, se você olhar para a Ásia, a linha sólida denota a mediana da expectativa de vida de cerca de 72 anos. Isso nos diz que metade de todos os países na Ásia tem uma expectativa de vida abaixo de 72 anos, enquanto a outra metade tem uma expectativa de vida acima de 72 anos.
Vamos calcular a mediana e a média da expectativa de vida para cada continente com um pouco mais de manipulação de dados e exibir os resultados na Tabela 6.
lifeExp_by_continent |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = c(Mediana, Média)
) |>
cols_align(
align = c("left"),
columns = continent
) |>
fmt_number(
decimals = 1,
columns = c(Mediana, Média)
) |>
tab_style(
style = list(
cell_text(align = "center")
),
locations = cells_column_labels(
columns = continent
)
)| continent | Mediana | Média |
|---|---|---|
| Africa | 52.9 | 54.8 |
| Asia | 72.4 | 70.7 |
| Americas | 72.9 | 73.6 |
| Europe | 78.6 | 77.6 |
| Oceania | 80.7 | 80.7 |
Observe a ordem da segunda coluna da mediana da expectativa de vida: África tem a mais baixa, as Américas e a Ásia vêm a seguir com medianas semelhantes, depois a Europa e, por fim, a Oceania. Esta ordenação corresponde à ordenação das linhas pretas sólidas dentro das caixas no nosso boxplot lado a lado na Figura 9.
Vamos agora voltar nossa atenção para os valores na terceira coluna de média. Usando a média da expectativa de vida da África de 54.8 como uma linha de base para comparação, vamos começar a fazer comparações com as médias de expectativa de vida dos outros quatro continentes e colocar esses valores na Tabela 7, que revisaremos mais adiante nesta seção.
- Para as Américas, é 73.6 - 54.8 = 18.8 anos mais alta.
- Para a Ásia, é 70.7 - 54.8 = 15.9 anos mais alta.
- Para a Europa, é 77.6 - 54.8 = 22.8 anos mais alta.
- Para a Oceania, é 80.7 - 54.8 = 25.9 anos mais alta.
gapminder2007 |>
group_by(continent) |>
summarise(
Média = mean(life_exp),
) |>
mutate(
"Diferença em relação à África" = Média - lifeExp_by_continent[[1,3]]
) |>
arrange(Média) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = c(Média, "Diferença em relação à África")
) |>
cols_align(
align = c("left"),
columns = continent
) |>
fmt_number(
decimals = 1,
columns = c(Média, "Diferença em relação à África")
) |>
tab_style(
style = list(
cell_text(align = "center")
),
locations = cells_column_labels(
columns = continent
)
)| continent | Média | Diferença em relação à África |
|---|---|---|
| Africa | 54.8 | 0.0 |
| Asia | 70.7 | 15.9 |
| Americas | 73.6 | 18.8 |
| Europe | 77.6 | 22.8 |
| Oceania | 80.7 | 25.9 |
Realize uma nova análise exploratória de dados com a mesma variável explicativa \(x\) sendo continent, mas com gdppercap como a nova variável de resultado \(y\). O que você pode dizer sobre as diferenças no PIB per capita entre continentes com base nesta exploração?
5.2.2 Regressão Linear
Na Subseção Seção 5.1.2, introduzimos a regressão linear simples, que envolve a modelagem da relação entre uma variável de resultado numérica \(y\) e uma variável explicativa numérica \(x\). No nosso exemplo de expectativa de vida, agora temos, em vez disso, uma variável explicativa categórica continent. Nosso modelo não fornecerá uma linha de regressão de “melhor ajuste” como na Figura 4, mas sim desvios relativos a uma linha de base para comparação.
Assim como fizemos na Subseção Seção 5.1.2 ao estudar a relação entre as notas de ensino e as pontuações de “beleza”, vamos exibir a tabela de regressão para este modelo. Lembre-se de que isso é feito em duas etapas:
- Primeiro, “ajustamos” o modelo de regressão linear usando a função
lm(y ~ x, data)e salvamos no objetolifeExp_model. - Obtemos a tabela de regressão aplicando a função
tidy()do pacotebroomaolifeExp_model.
lifeExp_model <- lm(life_exp ~ continent, data = gapminder2007)# A tibble: 5 × 7
term estimate std.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 54.8 1 53.4 0 52.8 56.8
2 continentAmericas 18.8 1.8 10.4 0 15.2 22.4
3 continentAsia 15.9 1.6 9.7 0 12.7 19.2
4 continentEurope 22.8 1.7 13.5 0 19.5 26.2
5 continentOceania 25.9 5.3 4.9 0 15.4 36.4lifeExp_model |>
tidy(conf.int = T) |>
mutate(
across(where(is.double),
\(x) round(x, 1))
) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = everything()
) |>
fmt_number(
decimals = 1,
)| term | estimate | std.error | statistic | p.value | conf.low | conf.high |
|---|---|---|---|---|---|---|
| (Intercept) | 54.8 | 1.0 | 53.4 | 0.0 | 52.8 | 56.8 |
| continentAmericas | 18.8 | 1.8 | 10.4 | 0.0 | 15.2 | 22.4 |
| continentAsia | 15.9 | 1.6 | 9.7 | 0.0 | 12.7 | 19.2 |
| continentEurope | 22.8 | 1.7 | 13.5 | 0.0 | 19.5 | 26.2 |
| continentOceania | 25.9 | 5.3 | 4.9 | 0.0 | 15.4 | 36.4 |
Vamos nos concentrar novamente nos valores nas colunas termo e estimativa da Tabela 8. Por que há agora 5 linhas? Vamos analisá-las uma a uma:
-
interceptcorresponde à expectativa de vida média dos países da África, que é de \(54.8\) anos. -
continentAmericascorresponde aos países das Américas e o valor \(+18.8\) é a mesma diferença na expectativa de vida média em relação à África, que exibimos na Tabela 7. Ou seja, a expectativa de vida média dos países das Américas é \(54.8 + 18.8 = 73.6\). -
continentAsiacorresponde aos países da Ásia e o valor +15,9 é a mesma diferença na expectativa de vida média em relação à África, que exibimos na Tabela 7. Ou seja, a expectativa de vida média dos países da Ásia é \(54.8 + 15.9 = 70.7\). -
continentEuropecorresponde aos países da Europa e o valor \(+22.8\) é a mesma diferença na expectativa de vida média em relação à África, que exibimos na Tabela 7. Ou seja, a expectativa de vida média dos países da Europa é \(54.8 + 22.8 = 77.6\). -
continentOceaniacorresponde aos países da Oceania e o valor +25,9 é a mesma diferença na expectativa de vida média em relação à África, que exibimos na Tabela 7. Ou seja, a expectativa de vida média dos países da Oceania é \(54.8 + 25.9 = 80.7\).
Para resumir, os cinco valores na coluna estimativa na Tabela 8 correspondem a linha de base para comparação com a média a África (o intercepto) e também desvios desse linha de base para os quatro continentes restantes: as Américas, Ásia, Europa e Oceania.
Você pode estar se perguntando por que a África foi escolhida como o grupo de linha de base para comparação. Isso acontece simplesmente porque ela vem primeiro em ordem alfabética dos cinco continentes. Por padrão, o R organiza fatores/variáveis categóricas em ordem alfanumérica. Você pode mudar esse grupo da linha de base para ser outro continente se manipular os “níveis” do fator da variável continente usando o pacote forcats. Veja o Capítulo 16 de R for Data Science (Wickham et al., 2023) para exemplos.
Agora, vamos escrever a equação para os nossos valores ajustados \(\hat{y} = \widehat{life\_\exp}\).
\[ \begin{aligned} \widehat{y} = \widehat{\text{life exp}} &= b_0 + b_{\text{Amer}}\cdot\mathnormal{1}_{\text{Amer}}(x) + b_{\text{Asia}}\cdot\mathnormal{1}_{\text{Asia}}(x) + \\ & \qquad b_{\text{Euro}}\cdot\mathnormal{1}_{\text{Euro}}(x) + b_{\text{Ocean}}\cdot\mathnormal{1}_{\text{Ocean}}(x)\\ &= 54.8 + 18.8\cdot\mathnormal{1}_{\text{Amer}}(x) + 15.9\cdot\mathnormal{1}_{\text{Asia}}(x) + \\ & \qquad 22.8\cdot\mathnormal{1}_{\text{Euro}}(x) + 25.9\cdot\mathnormal{1}_{\text{Ocean}}(x) \end{aligned} \]
Ufa! Isso parece assustador! Mas não se preocupe, pois uma vez que você entenda o que todos os elementos significam, as coisas se simplificam bastante. Primeiro, \(1_{A}(x)\) é o que é conhecido em matemática como uma “função indicadora”. Ela retorna apenas um dos dois possíveis valores, 0 e 1, onde
\[ \begin{equation*} \mathnormal1_{\text{A}}(x) = \left\{ \begin{aligned} &1 && \text{se } x \text{ está em } A \\ &0 && \text{se } x \text{ não está em } A \end{aligned} \right. \end{equation*} \]
No contexto de modelagem estatística, isso também é conhecido como uma variável dummy. No nosso caso, considere a primeira variável indicadora \(1_{Amer}(x)\). Esta função indicadora retorna 1 se um país está nas Américas e, caso contrário, 0:
\[ \begin{equation} \mathnormal1_{\text{Amer}}(x) = \left\{ \begin{aligned} &1 && \text{se o país } x \text{ está nas Américas} \\ &0 && \text{caso contrário} \end{aligned} \right. \end{equation} \]
Segundo, \(b_0\) corresponde ao intercepto como antes. Neste caso, é a expectativa de vida média de todos os países da África. Terceiro, os \(b_{Amer}\), \(b_{Asia}\), \(b_{Euro}\) e \(b_{Ocean}\) representam os 4 desvios relativos à linha de base para comparação na saída da regressão na Tabela 8: continentAméricas, continentÁsia, continentEuropa e continentOceania.
Vamos juntar tudo isso e calcular o valor ajustado \(\hat{y} = \widehat{life\_\exp}\) para um país na África. Como o país está na África, todas as quatro funções indicadoras \(1_{Amer}(x)\), \(1_{Asia}(x)\), \(1_{Euro}(x)\) e \(1_{Ocean}(x)\) serão iguais a 0, e, portanto:
\[ \begin{aligned} \widehat{\text{life exp}} &= b_0 + b_{\text{Amer}}\cdot\mathnormal{1}_{\text{Amer}}(x) + b_{\text{Asia}}\cdot\mathnormal{1}_{\text{Asia}}(x) + \\ & \qquad b_{\text{Euro}}\cdot\mathnormal{1}_{\text{Euro}}(x) + b_{\text{Ocean}}\cdot\mathnormal{1}_{\text{Ocean}}(x)\\ &= 54.8 + 18.8\cdot\mathnormal{1}_{\text{Amer}}(x) + 15.9\cdot\mathnormal{1}_{\text{Asia}}(x) + \\ & \qquad 22.8\cdot\mathnormal{1}_{\text{Euro}}(x) + 25.9\cdot\mathnormal{1}_{\text{Ocean}}(x)\\ &= 54.8 + 18.8\cdot 0 + 15.9\cdot 0 + 22.8\cdot 0 + 25.9\cdot 0\\ &= 54.8 \end{aligned} \]
Em outras palavras, tudo o que resta é o intercepto \(b_0\), correspondente à expectativa de vida média dos países africanos de \(54.8\) anos. A seguir, digamos que estamos considerando um país das Américas. Neste caso, apenas a função indicadora \(1_{Amer}(x)\) para as Américas será igual a 1, enquanto todas as outras serão iguais a 0, e, portanto:
\[ \begin{aligned} \widehat{\text{life exp}} &= 54.8 + 18.8\cdot\mathnormal{1}_{\text{Amer}}(x) + 15.9\cdot\mathnormal{1}_{\text{Asia}}(x) + 22.8\cdot\mathnormal{1}_{\text{Euro}}(x) + \\ & \qquad 25.9\cdot\mathnormal{1}_{\text{Ocean}}(x)\\ &= 54.8 + 18.8\cdot 1 + 15.9\cdot 0 + 22.8\cdot 0 + 25.9\cdot 0\\ &= 54.8 + 18.8 \\ & = 73.6 \end{aligned} \]
Isso é a expectativa de vida média para os países das Américas de \(73.6\) anos na Tabela 7. Note que o desvio da linha de base para comparação é \(+18.8\) anos.
Vamos fazer mais um. Digamos que estamos considerando um país da Ásia. Neste caso, apenas a função indicadora \(1_{Asia}(x)\) para a Ásia será igual a 1, enquanto todas as outras serão iguais a 0, e, portanto:
\[ \begin{aligned} \widehat{\text{life exp}} &= 54.8 + 18.8\cdot\mathnormal{1}_{\text{Amer}}(x) + 15.9\cdot\mathnormal{1}_{\text{Asia}}(x) + 22.8\cdot\mathnormal{1}_{\text{Euro}}(x) + \\ & \qquad 25.9\cdot\mathnormal{1}_{\text{Ocean}}(x)\\ &= 54.8 + 18.8\cdot 0 + 15.9\cdot 1 + 22.8\cdot 0 + 25.9\cdot 0\\ &= 54.8 + 15.9 \\ & = 70.7 \end{aligned} \]
Isso é a expectativa de vida média para os países asiáticos de \(70.7\) anos na Tabela 7. O desvio da linha de base para comparação aqui é \(+15.9\) anos.
Vamos generalizar essa ideia um pouco. Se ajustarmos um modelo de regressão linear usando uma variável explicativa categórica \(x\) que possui \(k\) possíveis categorias, a tabela de regressão retornará um intercepto e \(k - 1\) devios. No nosso caso, como há \(k = 5\) continentes, o modelo de regressão retorna um intercepto correspondente ao grupo grupo da linha de base para comparação, a África, e \(k - 1 = 4\) desvios correspondentes às Américas, Ásia, Europa e Oceania.
Compreender a saída de uma tabela de regressão quando se está usando uma variável explicativa categórica é um tópico com o qual os novatos em neste tipo de análise frequentemente têm dificuldades. O único remédio real para essas dificuldades é a prática constante. No entanto, uma vez que você se familiarize com a criação de modelos de regressão usando variáveis explicativas categóricas, você será capaz de incorporar muitas novas variáveis aos seus modelos, dada a grande quantidade de dados do mundo que são categóricos. Se você ainda se sentir com dificuldades neste ponto, no entanto, sugerimos que compare atentamente as Tabela 7 e Tabela 8 e observe como você pode calcular todos os valores de uma tabela usando os valores da outra.
Ajuste uma nova regressão linear usando lm(gdppercap ~ continent, data = gapminder2007), onde gdppercap é a nova variável de resultado \(y\). Obtenha informações sobre a linha de “melhor ajuste” a partir da tabela de regressão aplicando a função tidy(). Como os resultados da regressão se alinham com os resultados da sua análise exploratória de dados anterior?
5.2.3 Valores ajustados/observados e resíduos
Lembre-se da Seção 5.1.3, onde definimos os três conceitos a seguir:
- Valores observados \(y\), ou o valor observado da variável de resultado.
- Valores ajustados \(\hat{y}\), ou o valor na linha de regressão para um dado valor de \(x\).
- Resíduos \(y - \hat{y}\), ou o erro entre o valor observado e o valor ajustado.
Obtivemos esses valores e outros usando a função augment() do pacote broom. Desta vez, no entanto, vamos adicionar a variável country como uma variável de identificação na saída. Para isso, utilizamos o código a seguir que pode ser dividido em 3 passos:
- A função
select(country)é usada para selecionar apenas a colunacountrydo banco de dadosgapminder2007. - A função
augment(lifeExp_model)cria um banco de dados com as variáveis que foram utilizads no modelo (life_expecontinent) e adiciona informações sobre cada observação no banco de dados. Neste caso, estamos interessados nos valores ajustados (.fitted) e nos resíduos. (.resid).bind_cols(augment(lifeExp_model))é então usada para adicionar a colunacountryao banco de dados gerados com a funçãoaugment(). - Por fim,
select(-c(.hat:.std.resid))é empregado para retirar do banco de dados colunas que não vamos utilizar por hora.
gapminder2007 |>
select(country) |>
bind_cols(augment(lifeExp_model)) |>
select(-c(.hat:.std.resid))# A tibble: 142 × 5
country life_exp continent .fitted .resid
<fct> <dbl> <fct> <dbl> <dbl>
1 Afghanistan 43.8 Asia 70.7 -26.9
2 Albania 76.4 Europe 77.6 -1.23
3 Algeria 72.3 Africa 54.8 17.5
4 Angola 42.7 Africa 54.8 -12.1
5 Argentina 75.3 Americas 73.6 1.71
6 Australia 81.2 Oceania 80.7 0.516
7 Austria 79.8 Europe 77.6 2.18
8 Bahrain 75.6 Asia 70.7 4.91
9 Bangladesh 64.1 Asia 70.7 -6.67
10 Belgium 79.4 Europe 77.6 1.79
# ℹ 132 more rowsVamos colocar esses dados em uma tabela:
gapminder2007 |>
select(country) |>
bind_cols(augment(lifeExp_model)) |>
select(-c(.hat:.std.resid)) |>
slice(1:10) |>
gt() |>
tab_options(
table.width = pct(100),
heading.align ="center"
) |>
cols_align(
align = c("center"),
columns = everything()
) |>
fmt_number(
decimals = 2,
columns = c(life_exp:.resid)
)| country | life_exp | continent | .fitted | .resid |
|---|---|---|---|---|
| Afghanistan | 43.83 | Asia | 70.73 | −26.90 |
| Albania | 76.42 | Europe | 77.65 | −1.23 |
| Algeria | 72.30 | Africa | 54.81 | 17.49 |
| Angola | 42.73 | Africa | 54.81 | −12.08 |
| Argentina | 75.32 | Americas | 73.61 | 1.71 |
| Australia | 81.23 | Oceania | 80.72 | 0.52 |
| Austria | 79.83 | Europe | 77.65 | 2.18 |
| Bahrain | 75.64 | Asia | 70.73 | 4.91 |
| Bangladesh | 64.06 | Asia | 70.73 | −6.67 |
| Belgium | 79.44 | Europe | 77.65 | 1.79 |
Observe na Tabela 9 que .fitted contém os valores ajustados \(\hat{y}\). Se você olhar atentamente, há apenas cinco valores possíveis para .fitted. Estes correspondem às cinco médias de expectativa de vida para os cinco continentes que exibimos na Tabela 7 e calculamos usando os valores na coluna de estimativa da tabela de regressão na Tabela 8.
A coluna .resid é simplesmente \(y - \hat{y} =\) life_exp \(-\) .fitted. Esses valores podem ser interpretados como o desvio da expectativa de vida de um país em relação à média de expectativa de vida de seu continente. Por exemplo, olhe para a primeira linha da Tabela 9 correspondente ao Afeganistão. O resíduo de `\(y - \hat{y} = 43.8 - 70.7 = -26.9\) está nos dizendo que a expectativa de vida do Afeganistão é impressionantes 26,9 anos menor do que a média da expectativa de vida de todos os países asiáticos. Isso pode ser parcialmente explicado pelos muitos anos de guerra que o país sofreu.
Usando a funcionalidade de ordenação do visualizador de planilhas do RStudio ou as ferramentas de manipulação de dados que você aprendeu no Capítulo 3, identifique os cinco países com os cinco menores (mais negativos) resíduos. O que esses resíduos negativos dizem sobre a expectativa de vida desses países em relação à expectativa de vida de seus continentes?
Repita esse processo, mas identifique os cinco países com os cinco maiores (mais positivos) resíduos. O que esses resíduos positivos dizem sobre a expectativa de vida desses países em relação à expectativa de vida de seus continentes?
5.3 Assuntos relacionados
5.3.1 Correlação não é necessariamente causalidade
Ao longo deste capítulo, fomos cautelosos ao interpretar os coeficientes de inclinação da regressão. Sempre discutimos o efeito “associado” de uma variável explicativa \(x\) em uma variável de resultado \(y\). Por exemplo, nossa afirmação da Seção 5.1.2 de que “para cada aumento de 1 unidade em bty_avg, há um aumento associado de, em média, 0.067 unidades de score”. Incluímos o termo “associado” para sermos extremamente cuidadosos em não sugerir que estamos fazendo uma declaração causal. Então, enquanto a pontuação de “beleza” bty_avg está positivamente correlacionada com a pontuação de ensino, não podemos necessariamente fazer declarações sobre o efeito causal direto das pontuações de “beleza” na pontuação de ensino sem mais informações sobre como este estudo foi conduzido. Aqui está outro exemplo: um médico não tão bom passa pelos prontuários e descobre que pacientes que dormiram calçados com seus sapatos tendiam a acordar mais com dores de cabeça. Então, esse médico declara: “Dormir com sapatos causa dores de cabeça!”.

No entanto, há uma boa chance de que, se alguém está dormindo com os sapatos, é potencialmente porque bebeu demais e está embrigado. Além disso, níveis mais altos de consumo de álcool levam a mais ressacas e, portanto, a mais dores de cabeça. A quantidade de consumo de álcool aqui é o que é conhecido como uma variável confundidora/oculta. Ela “se esconde” nos bastidores, confundindo a relação causal (se houver) de “dormir de sapatos” com “acordar com dor de cabeça”. Podemos resumir isso na Figura 11 com um gráfico de causalidade onde:
-
Yé uma variável de resposta: “acordar com dor de cabeça”. -
Xé uma variável de tratamento cujo efeito causal estamos interessados: “dormir de sapatos”.
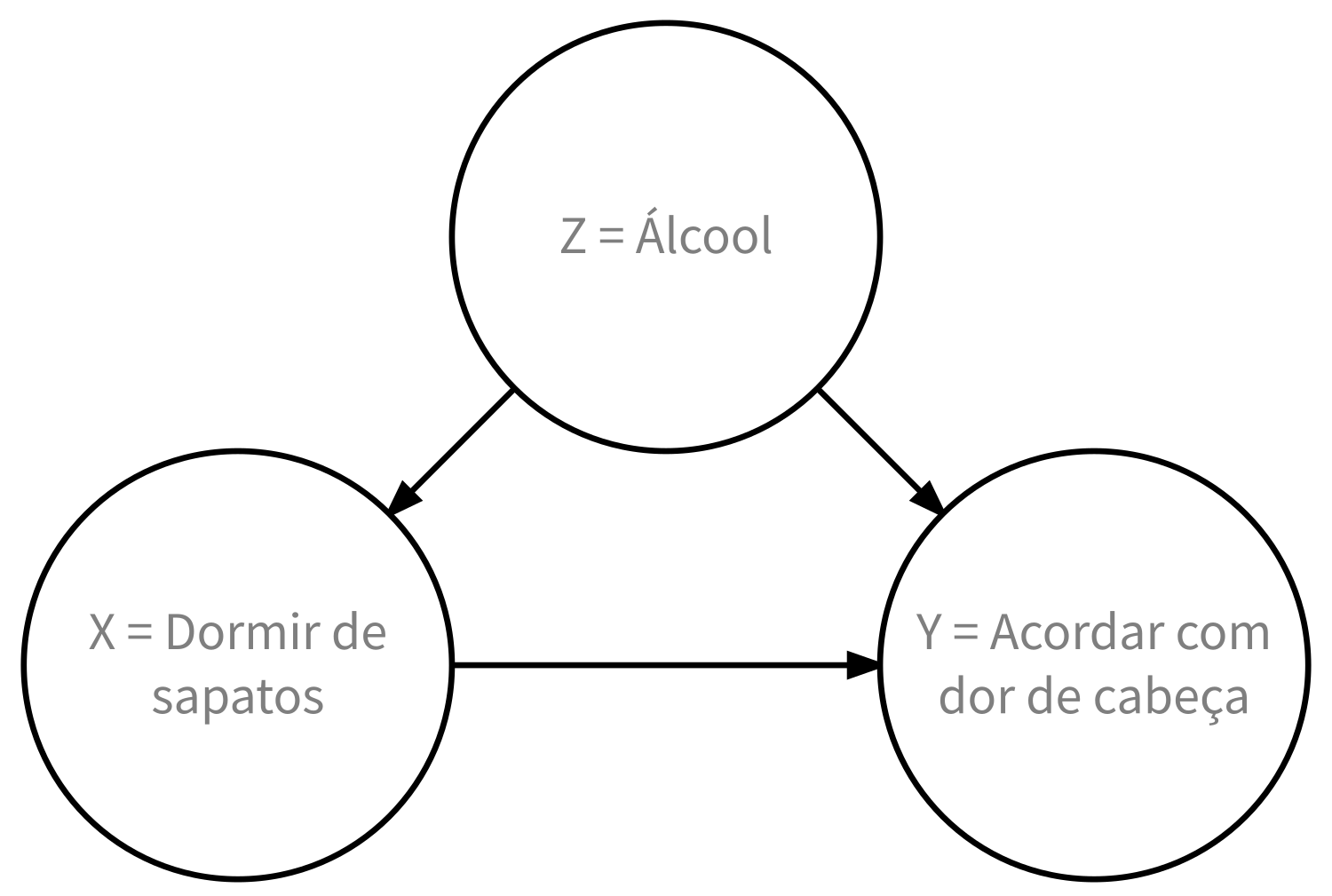
Para estudar a relação entre Y e X, poderíamos usar um modelo de regressão onde a variável de resultado é definida como Y e a variável explicativa é definida como X, como você tem feito ao longo deste capítulo. No entanto, a Figura 11 também inclui uma terceira variável com setas apontando para X e Y:
- Z é uma variável confundidora que afeta tanto X quanto Y, confundindo assim a relação entre eles. Aqui a variável confundidora é o álcool.
O álcool fará com que as pessoas tenham mais probabilidade de dormir com seus sapatos e também mais probabilidade de acordar com dor de cabeça. Portanto, qualquer modelo de regressão da relação entre X e Y também deve usar Z como uma variável explicativa. Em outras palavras, nosso médico precisa levar em conta quem estava bebendo na noite anterior. No próximo capítulo, começaremos a abordar modelos de regressão múltipla que nos permitem incorporar mais de uma variável em nossos modelos de regressão.
Estabelecer causalidade é um problema complicado e frequentemente exige experimentos cuidadosamente desenhados ou métodos para controlar os efeitos de variáveis confundidoras. Ambas as abordagens tentam, da melhor maneira possível, levar em conta todas as variáveis confundidoras possíveis ou negar seu impacto. Isso permite que os pesquisadores se concentrem apenas na relação de interesse: a relação entre a variável de resultado Y e a variável de tratamento X.
Ao ler notícias, tenha cuidado para não cair na armadilha de pensar que correlação necessariamente implica causalidade. Confira o site Spurious Correlations para alguns exemplos bastante cômicos de variáveis que estão correlacionadas, mas definitivamente não estão relacionadas causalmente.
5.3.2 Linha de melhor ajuste
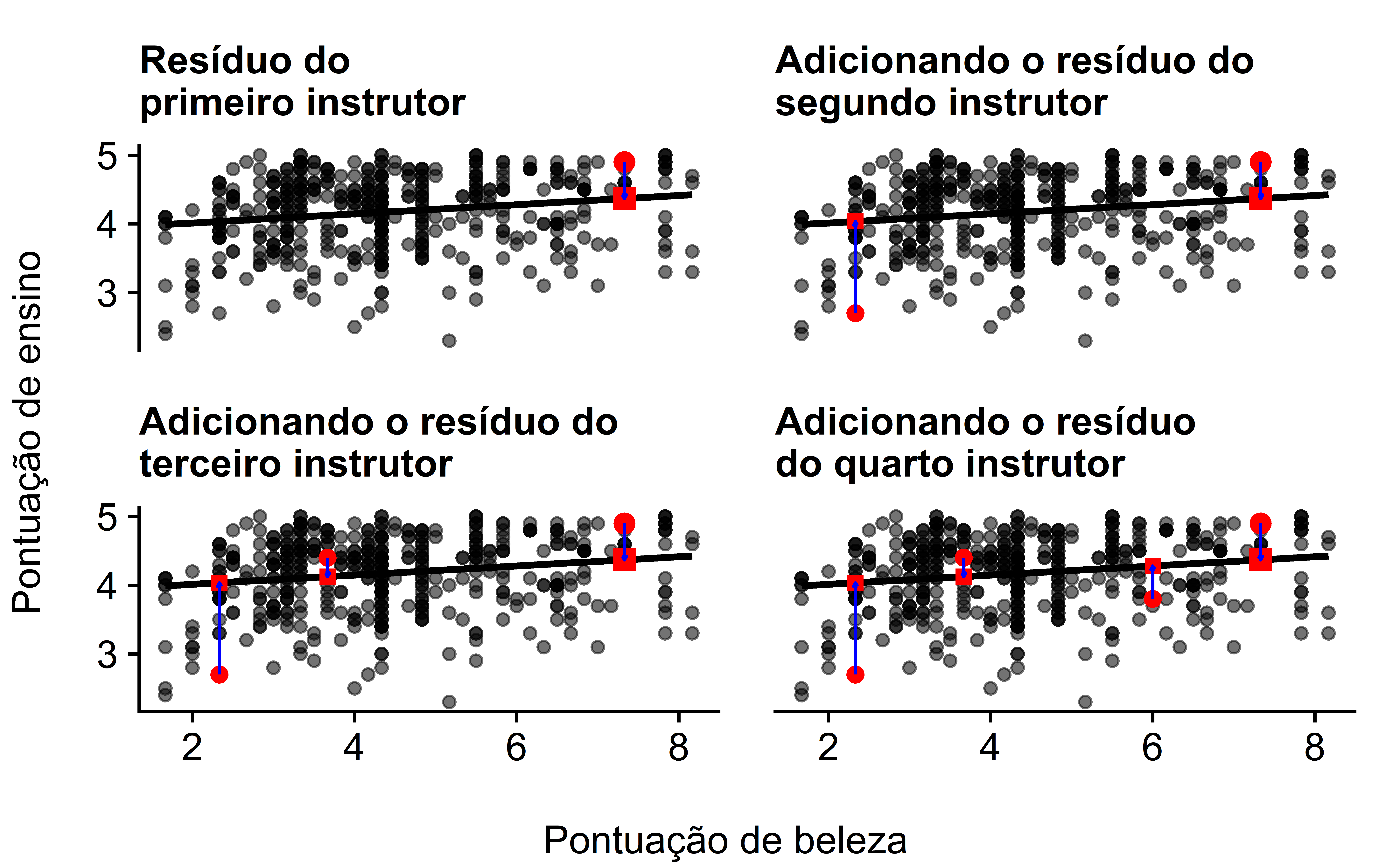
Linhas de regressão também são conhecidas como linhas de “melhor ajuste”. Mas o que queremos dizer com “melhor”? Vamos descompactar os critérios usados na regressão para determinar o “melhor”. Lembre-se da Figura 6, onde, para um instrutor com uma pontuação de “beleza” de \(x = 7.333\), marcamos o valor observado \(y\) com um círculo, o valor ajustado \(\hat{y}\) com um quadrado, e o resíduo \(y - \hat{y}\) com uma seta. Reexibimos a Figura 6 no gráfico superior esquerdo da Figura 14, além de mais três instrutores de curso escolhidos arbitrariamente.
Os outros três gráficos referem-se a:
Um curso cujo instrutor tinha uma pontuação de “beleza” \(x = 2.333\) e pontuação de ensino \(y = 2.7\). O resíduo neste caso é \(2.7 - 4.036 = -1.336\), que marcamos com uma nova seta azul no gráfico superior direito.
Um curso cujo instrutor tinha uma pontuação de “beleza” \(x = 3.667\) e pontuação de ensino \(y = 4.4\). O resíduo neste caso é \(4.4 - 4.125 = 0.2753\), que marcamos com uma nova seta azul no gráfico inferior esquerdo.
Um curso cujo instrutor tinha uma pontuação de “beleza” \(x = 6\) e pontuação de ensino \(y = 3.8\). O resíduo neste caso é \(3.8 - 4.28 = -0.4802\), que marcamos com uma nova seta azul no gráfico inferior direito.
Agora digamos que repetimos esse processo de calcular resíduos para todos os 463 instrutores de cursos, depois elevamos todos os resíduos ao quadrado e, em seguida, os somamos. Chamamos o valor obtido de soma dos quadrados dos resíduos, que é uma medida da falta de ajuste de um modelo. Valores maiores da soma dos quadrados dos resíduos indicam uma maior falta de ajuste. Isso corresponde a um modelo com pior ajuste.
Se a linha de regressão se ajustar perfeitamente a todos os pontos, então a soma dos resíduos quadrados é 0. Isso porque se a linha de regressão se ajustar perfeitamente a todos os pontos, então o valor ajustado \(\hat{y}\) iguala o valor observado \(y\) em todos os casos, e, portanto, o resíduo \(y - \hat{y} = 0\) em todos os casos, e a soma de um grande número de 0s ainda é 0.
Além disso, de todas as linhas possíveis que podemos desenhar através da nuvem de 463 pontos, a linha de regressão minimiza esse valor. Em outras palavras, a regressão e seus valores ajustados correspondentes \(\hat{y}\) minimizam a soma dos resíduos quadrados:
\[ \sum_{i=1}^{n}(y_i - \widehat{y}_i)^2 \]
Vamos usar nossas ferramentas de manipulação de dados do Capítulo 3 para calcular exatamente a soma dos resíduos quadrados:
score_model <- lm(score ~ bty_avg,
data = evals_ch5)
pontos_da_regressao <- score_model |>
augment()
pontos_da_regressao# A tibble: 463 × 8
score bty_avg .fitted .resid .hat .sigma .cooksd .std.resid
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 4.7 5 4.21 0.486 0.00247 0.535 0.00103 0.911
2 4.1 5 4.21 -0.114 0.00247 0.535 0.0000560 -0.213
3 3.9 5 4.21 -0.314 0.00247 0.535 0.000427 -0.587
4 4.8 5 4.21 0.586 0.00247 0.535 0.00149 1.10
5 4.6 3 4.08 0.520 0.00403 0.535 0.00192 0.974
6 4.3 3 4.08 0.220 0.00403 0.535 0.000343 0.412
7 2.8 3 4.08 -1.28 0.00403 0.532 0.0116 -2.40
8 4.1 3.33 4.10 -0.00244 0.00325 0.535 0.0000000340 -0.00457
9 3.4 3.33 4.10 -0.702 0.00325 0.534 0.00282 -1.32
10 4.5 3.17 4.09 0.409 0.00361 0.535 0.00106 0.765
# ℹ 453 more rowspontos_da_regressao |>
mutate(
residuos_ao_quadrado = .resid^2
) |>
summarise(
soma_dos_residuos_ao_quadrado = sum(residuos_ao_quadrado)
)# A tibble: 1 × 1
soma_dos_residuos_ao_quadrado
<dbl>
1 132.Qualquer outra linha reta desenhada na figura resultaria em uma soma dos resíduos quadrados maior do que 132. Este é um fato matematicamente garantido que você pode provar usando cálculo e álgebra linear. É por isso que nomes alternativos para a linha de regressão linear são a linha de melhor ajuste e a linha de mínimos quadrados. Por que elevamos os resíduos ao quadrado (ou seja, os comprimentos das setas)? Para que tanto os desvios positivos quanto os negativos do mesmo montante sejam tratados igualmente. Dito isso, embora tomar o valor absoluto dos resíduos também trataria os desvios positivos e negativos do mesmo montante igualmente, o quadrado dos resíduos é usado por razões relacionadas ao cálculo: tomar derivadas e minimizar funções. Para aprender mais, sugerimos que consulte um livro-texto sobre estatística matemática.
Observe na Figura 13 que existem 3 pontos marcados com bolas pretas e:
- A linha de regressão sólida azul de “melhor” ajuste
- Uma linha pontilhada vermelha escolhida arbitrariamente
- Outra linha tracejada verde escolhida arbitrariamente
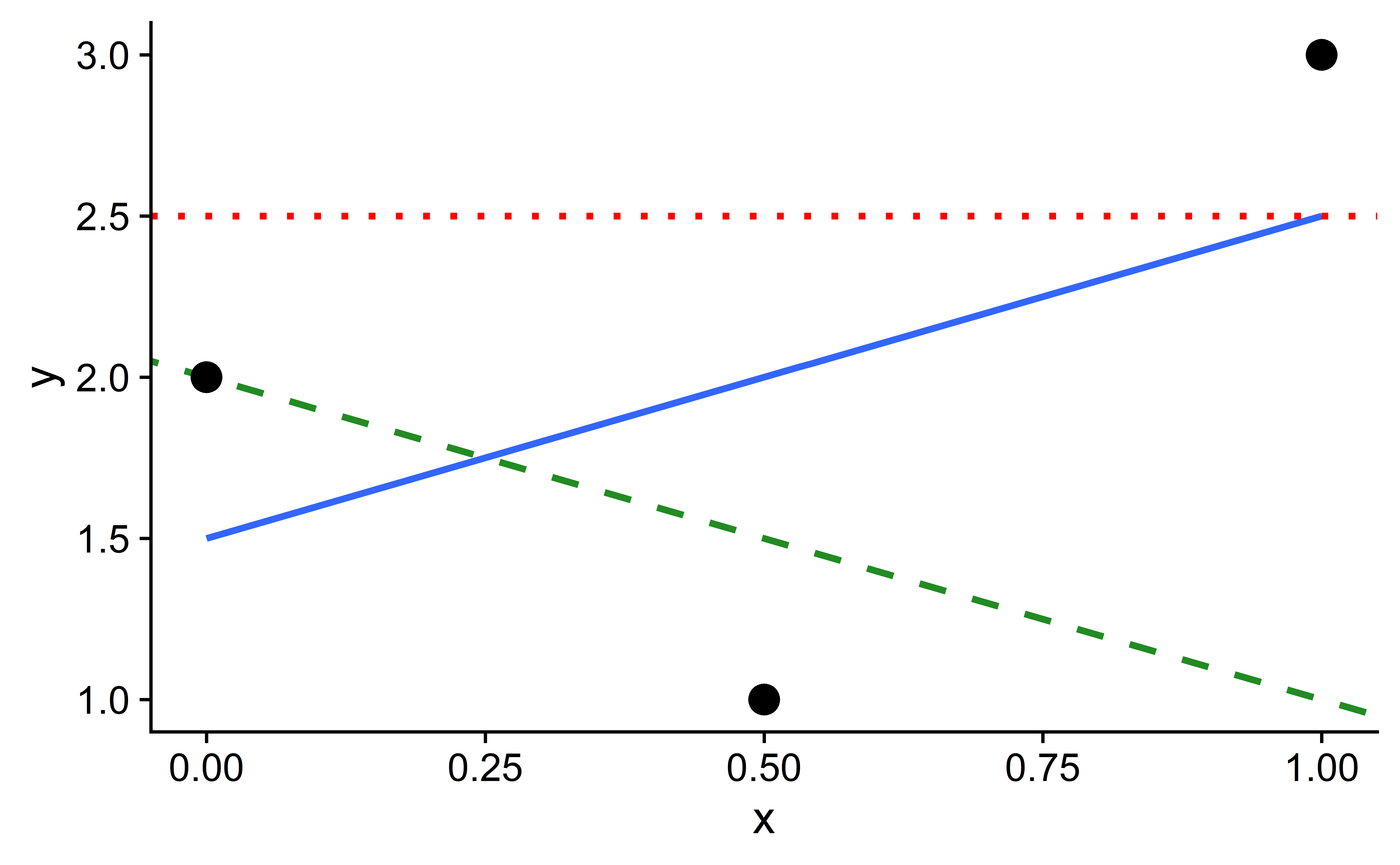
Calcule a soma dos quadrados dos resíduos manualmente para cada linha e mostre que, dessas três linhas, a linha de regressão em azul tem o menor valor.
5.4 Conclusão
5.4.1 Fontes adicionais
Como sugerimos na Seção 5.1.1, interpretar coeficientes que não estão próximos aos valores extremos de -1, 0 e 1 pode ser um pouco subjetivo. Para ajudar a desenvolver seu senso sobre coeficientes de correlação, sugerimos que você jogue o jogo chamado “Guess the Correlation” (Adivinhe a Correlação), disponível em http://guessthecorrelation.com/{target=“_blank”}.
5.4.2 O que virá a seguir?
Neste capítulo, você estudou a regressão básica, onde ajustou modelos que tinham apenas uma variável explicativa. No Capítulo 6, estudaremos a regressão múltipla, onde nossos modelos de regressão poderão agora ter mais de uma variável explicativa! Em particular, consideraremos dois cenários: modelos de regressão com uma variável explicativa numérica e uma categórica e modelos de regressão com duas variáveis explicativas numéricas. Isso permitirá que você construa modelos mais sofisticados e poderosos, com a expectativa de explicar melhor sua variável de resultado \(y\).
Referências
Notas de rodapé
Para fins de formatação neste livro, o histograma que geralmente é impresso com `skim()` foi removido. Isso pode ser feito usando `focus()`, que atua como a função `select()`, mas para selecionar colunas dos resultados analisados. Para maiores informações, consulte a página de referência do pacote aqui.↩︎
Note que o símbolo \(\cdot\) é equivalente ao símbolo matemático “multiplicar por” \(\times\). Usaremos o símbolo \(\cdot\) no restante deste livro, pois ele é mais sucinto.↩︎